
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131132.html
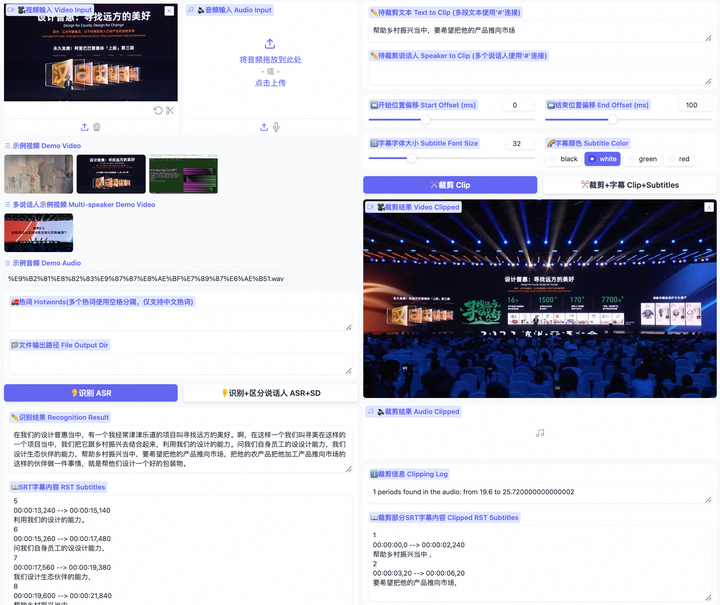
项目简介Funclip 是阿里巴巴通义实验室开源的一款视频剪辑工具,专门用于精准、便捷的视频切片。它能够自动识别视频中的中文语音并允许用户根据语音内容来裁剪视频。该工具使用了阿里巴巴语音识别模型FunASR Paraformer-Large确保了剪辑的精准性。你可以根据识别结果选择文本片段或说话人进行视频裁剪。使得视频剪辑变得非常方便。Funclip不仅支持中文,未来还将支持英文视频剪辑,是视频内...

Streamer-Sales是一个为直播带货主播量身定制的智能工具。它能够智能分析商品特性,自动创作出引人入胜的解说词,从而有效增强商品的吸引力和提升销售业绩。它还具备多种交互功能,比如将主播的语音实时转换为文字,便于与观众进行更直接的交流。它还能够生成富有感情色彩的语音,让商品介绍更加生动,以及创造虚拟主播的视频,为观众带来更加直观和有趣的购物体验。具体功能1. 主播文案生成:系统能够基于商品特...
摘要:可预见的未来激情赛事已经过半,阿里云视频技术在本次世界杯中也成功落地,而这并不是结局,这是将视频应用于体育行业以及更多其他行业的开端。 本届世界杯互联网直播的顺利进行,离不开各大云计算厂商的支持。在这其中,阿里云是当之无愧的C位,除了优酷外,阿里云还支撑了CNTV、CCTV5客户端,为全网70%的世界杯直播流量保驾护航。 对于世界杯这种超大观看量级、超强影响力的重要体育赛事,阿里云一直...
摘要:文本谷歌神经机器翻译去年,谷歌宣布上线的新模型,并详细介绍了所使用的网络架构循环神经网络。目前唇读的准确度已经超过了人类。在该技术的发展过程中,谷歌还给出了新的,它包含了大量的复杂案例。谷歌收集该数据集的目的是教神经网络画画。 1. 文本1.1 谷歌神经机器翻译去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。关键结果:与...

阅读 11673·2025-06-19 16:48
阅读 3114·2025-05-12 19:38
阅读 3992·2025-04-29 17:46
阅读 14805·2025-03-21 11:44
阅读 2135·2025-02-19 18:27
阅读 1989·2025-02-19 18:21
阅读 2096·2025-02-19 13:50
阅读 3191·2025-02-13 22:35




