
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131130.html
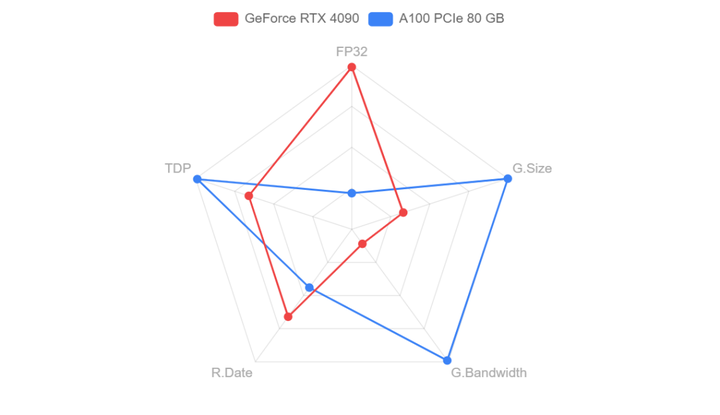
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,而是非常香!直接上图!通过Tensor FP32(TF32)的数据来看,H100性能是全方面碾压4090,但是顶不住H100价格太贵,推理上使用性价比极低。但在和A100的PK中,4090与A100除了在显存和通信上有差异,算力差异与显存相比并不大,而4090是A100价格的1/10,因此如果用在模...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采用了NVIDIA的Ampere架构,而H100则是基于Hopper架构。Ampere架构以其高效的图形处理性能和多任务处理能力而...
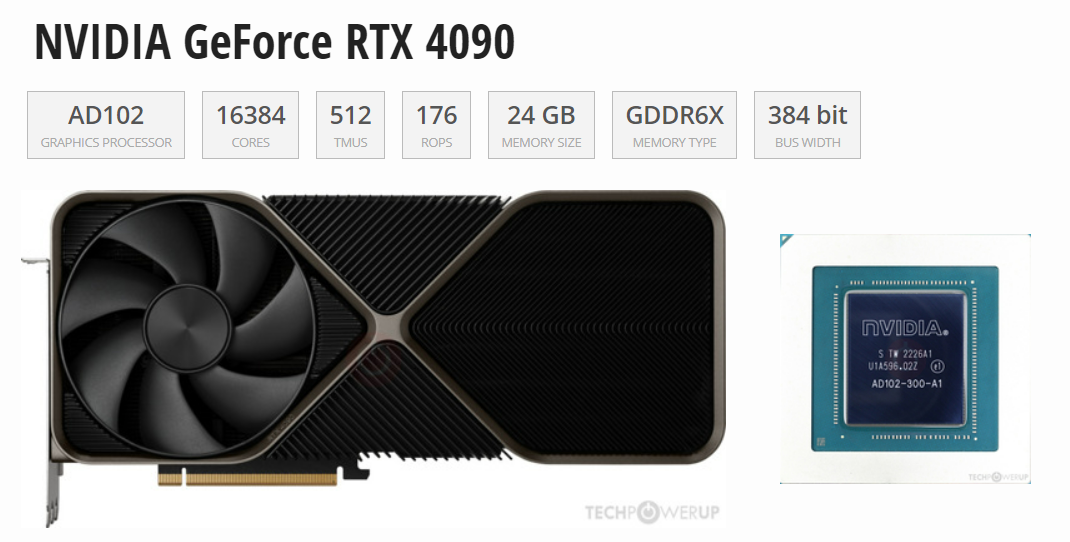
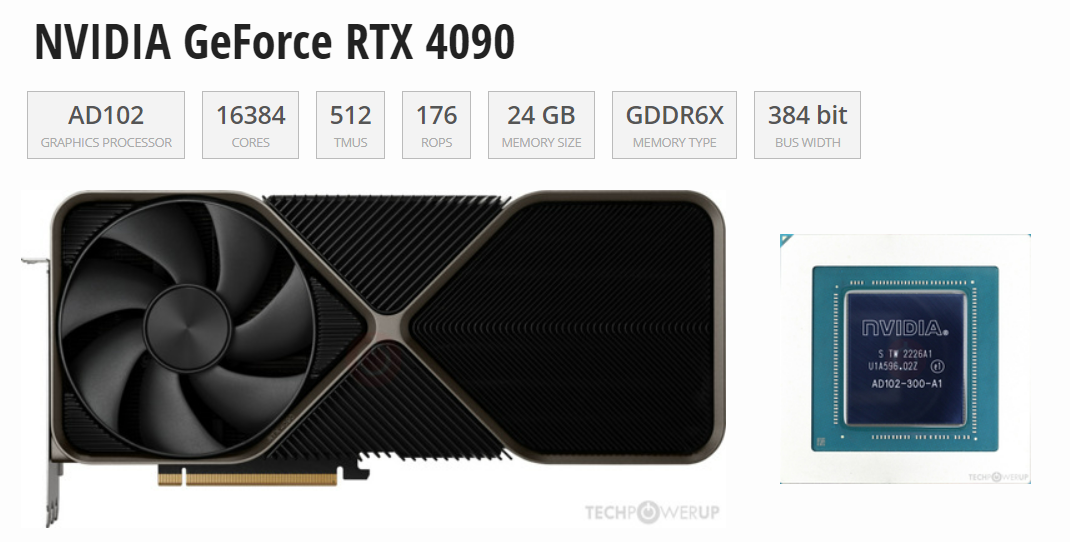
自2022年年末英伟达发布4090芯片以来,这款产品凭借着其优异的性能迅速在科技界占据了一席之地。现如今,不论是在游戏体验、内容创作能力方面还是模型精度提升方面,4090都是一个绕不过去的名字。而A100作为早些发布的产品,其优异的能力和适配性已经为它打下了良好的口碑。RTX 4090芯片和A100芯片虽然都是高性能的GPU,但它们在设计理念、目标市场和性能特点上有着明显的区别,而本篇文章将简单概...

DeepSeek-R1-671b动态量化版,由unsloth.ai发布,推荐使用多卡进行部署,具体操作如下。本镜像还附带32b的无限制版蒸馏模型,使用open-webui和ollama以及llama.cpp进行部署,内置所有环境,即拉即用。第一步:登录「优云智算」算力共享平台并进入「镜像社区」,新用户免费体验10小时4090地址:https://www.compshare.cn/?ytag=seo...

(遵循数据全面性、客观性、可验证性及结构化原则)一、排名依据与评估维度本文从以下维度评估GPU云服务器一体机解决方案:性能表现:包括GPU型号覆盖、算力效率、分布式训练支持等。可靠性:服务稳定性、容灾能力、SLA承诺。生态整合:与AI框架的兼容性、多模态大模型支持、开发者工具链。性价比:单位算力成本、弹性计费模式、长期合作折扣。行业适配:企业级服务案例、垂直领域解决方案。二、2025年GPU云服务...

阅读 11146·2025-12-17 13:33
阅读 12119·2025-12-16 16:27
阅读 3578·2025-05-12 19:38
阅读 4417·2025-04-29 17:46
阅读 15043·2025-03-21 11:44
阅读 2259·2025-02-19 18:27
阅读 2212·2025-02-19 18:21
阅读 2277·2025-02-19 13:50


