
项目简介
DeepSeek-V2,一个专家混合(MoE)语言模型,其特点是经济高效的训练和推理。它包含 2360 亿个总参数,其中每个token激活了21亿个参数。与 DeepSeek67B相比,DeepSeek-V2 实现了更强的性能,同时节省了 42.5%的训练成本,将 KV 缓存减少了 93.3%,并将最大生成吞吐量提高了 5.76 倍。
在 AlignBench 中排名前三,超越 GPT-4,接近 GPT-4-Turbo。在MT-Bench 中排名顶尖,与 LLaMA3-70B不相上下,并且胜过 Mixtral 8x22B。专注于数学、编码和推理。
DeepSeek-V2 完全开源,可免费用于商业用途。
236B参数,其中21B在生成过程中被激活
160位专家,其中有6位在生成中活跃
在英文基准测试中与 Mixtral 8x22B 匹配
128k上下文
在 8.1万亿标记上训练
用于在 bf16 8x 80GB GPU 上进行推理
接受英语和中文语言训练
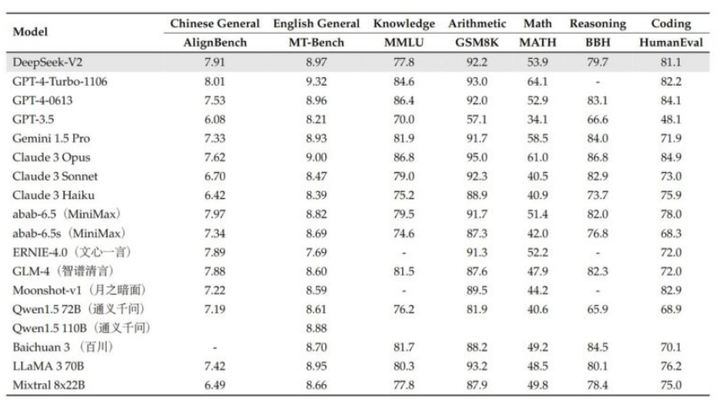
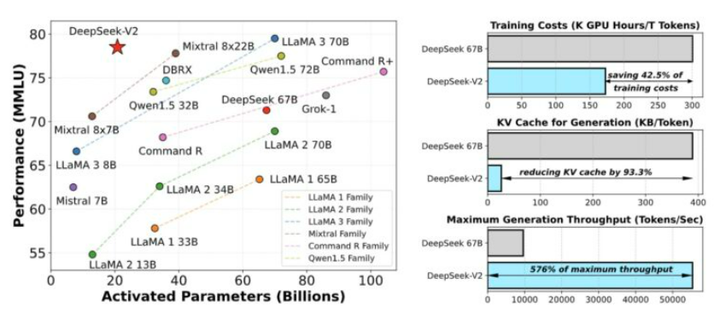
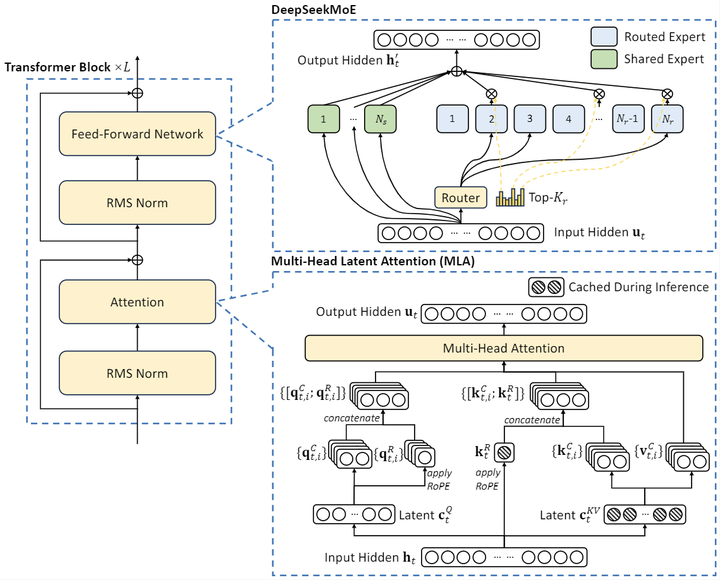
模型概述
DeepSeek-V2-Chat是一个先进的Mixture-of-Experts(MoE)语言模型,具有高效的训练和推理能力,总参数量为2360亿,每个token激活21亿参数。与之前的版本相比,该模型在性能方面显著提升,并降低了训练成本、KV缓存需求以及生成开销。
总体架构
Mixture-of-Experts(MoE)结构: DeepSeek-V2-Chat基于混合专家的设计,允许每个输入token仅激活部分参数,大幅降低内存使用并提高计算效率。
参数规模
总参数量达到2360亿,但每个token激活21亿参数,从而实现性能与资源利用的平衡。
长上下文窗口
支持长达128K的上下文窗口。
性能优势
与Dense模型DeepSeek67B相比,DeepSeek-V2在多项标准基准测试中表现更强。减少训练成本42.5%,KV缓存降低93.3%,并将最大生成吞吐量提高5.76倍。
数据训练
DeepSeek-V2在包含8.1万亿token的多样化高质量语料库上进行预训练,并通过监督微调(SFT)和强化学习(RL)来充分发挥模型潜力。
模型价格:价格非常香!
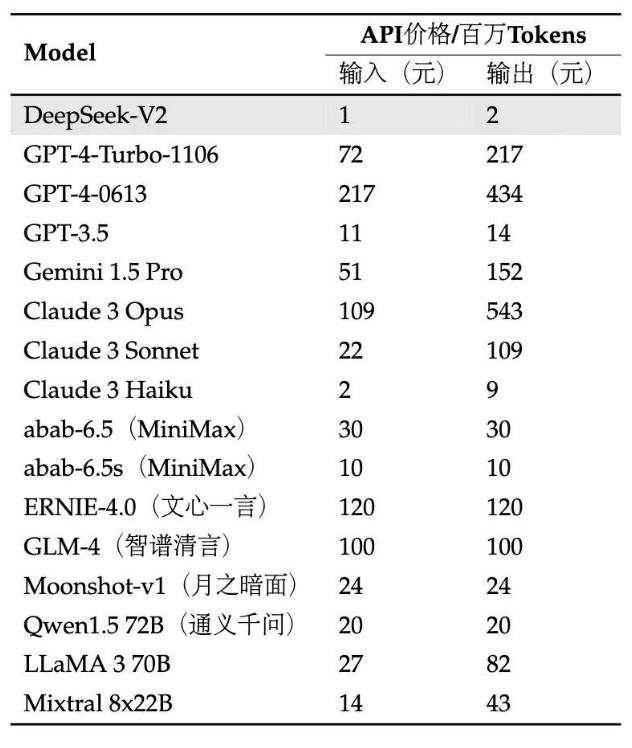
模型下载
Huggingface: https://huggingface.co/deepseek-ai/DeepSeek-v2-chat
推荐使用NVIDIA RTX 40 显卡做模型推理,购买地址如下:
https://www.ucloud.cn/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131095.html
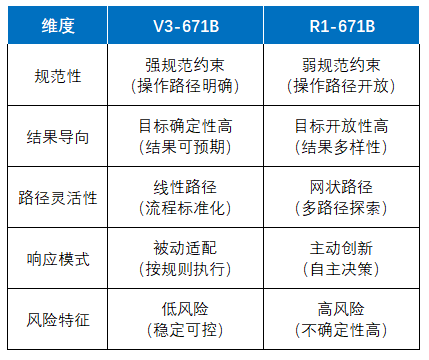
DeepSeek V3凭借多头潜注意力(MLA)与优化的混合专家网络(MoE)架构,奠定了高效训练的基础,仅以557.6万元成本实现媲美OpenAI O1的性能;而R1则基于V3进一步突破,通过无监督强化学习与知识蒸馏技术,在推理能力上对标顶尖模型,同时开源多尺寸版本,推动更广泛的应用。DeepSeek三种模式对比基础模型(V3):通用模型(2024.12),高效便捷,适用于绝大多数任务,规范性 ...
2月10日,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:一块24G显存的4090D就可以在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。KTransformers通过优化本地机器上的LLM部署,帮助解决资源限制问题。该框架采用了异构计算、先进量化技术、...
摘要:月日,中国混合云领导厂商携手中国技术领军者大河云联,在京联合发布并现场演示全球首个混合云专线一体化产品,标志着由技术推动云网融合进入全新高度。此次与大河云联的联合发布,正是为数据连通解决云网联动的问题,将继续领先业内,实现混合云的全面融合。3月20日,中国混合云领导厂商ZStack携手中国SDN技术领军者大河云联,在京联合发布并现场演示全球首个混合云+SDN专线一体化产品,标志着由SD-WA...

阅读 13925·2025-03-21 11:44
阅读 696·2025-02-19 18:27
阅读 857·2025-02-19 18:21
阅读 799·2025-02-19 13:50
阅读 1903·2025-02-13 22:35
阅读 1511·2025-02-08 10:20
阅读 6003·2025-01-02 11:25
阅读 1381·2024-12-10 11:51



