
随着人工智能的持续火热,好的加速卡成为了各行业的重点关注对象,因为在AI机器学习中,通常涉及大量矩阵运算、向量运算和其他数值计算。这些计算可以通过并行处理大幅提高效率,而高端显卡的存在,使得在处理要求拥有大量算力的任务时,变得不那么难了。
这篇文章大家伙聊聊RTX4090这款显卡,4090论性能不如H100,论价格不如3090,那为什么能成为众多企业、高校科研人员眼中的香饽饽?
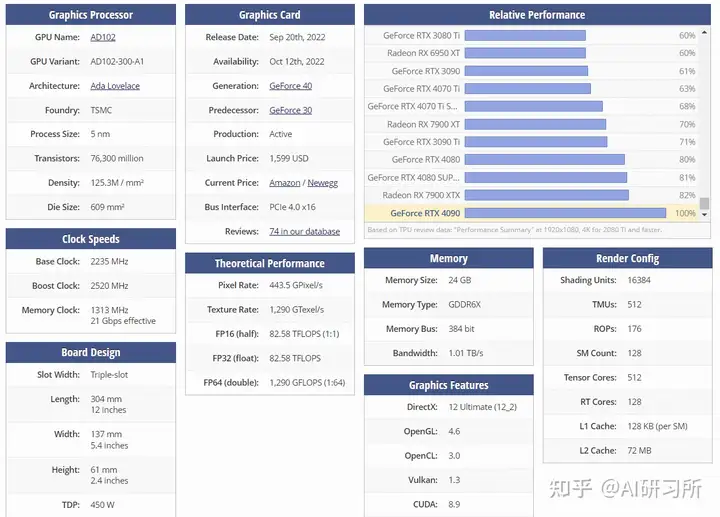
RTX 4090是基于NVIDIA的Ada Lovelace架构,这一架构在图形处理能力和并行计算能力上都有显著的提升。特别是其Tensor Cores(张量核心),专为AI计算优化设计,可以极大加速深度学习模型的训练和推理过程。相较于前代产品,RTX 4090的AI处理速度更快,FP16算力达到了330TFlops,FP32算力达到了83FPlops,能更高效地处理复杂的算法和大规模的数据集。
| 4090 | 参数 |
|---|---|
| 显卡芯片 | GeForce RTX 4090 |
| CUDA核心 | 16384个 |
| 显存容量 | 24GB GDDR6X |
| 显存位宽 | 384bit |
| 核心频率 | 2230-2520MHz |
| 显存频率 | 21000MHz(21Gbps) |
| 内存带宽 | 高达 1TB/s |
| 通信带宽 | 64 GB/s |
| FP16算力 | 330 Tflops |
| FP32算力 | 83 Tflops |
Ada Lovelace架构提供了更高的效率和更强的计算密度。RTX 4090利用这一架构,带来了改进的Ray Tracing Cores(光线追踪核心)和第三代Tensor Cores,这使得它在执行机器学习任务时,能够提供更快的响应速度和更高的精度。此外,这种显卡还引入了多项新技术,如DLSS 3(深度学习超级采样),进一步提升了AI渲染能力。
RTX 4090配备了24GB的GDDR6X内存,这为处理大型神经网络模型和复杂的数据集提供了充足的空间。高达1TB的内存带宽保证了数据在处理过程中的快速传输,这对于需要实时分析和决策的AI应用尤为重要。
NVIDIA长期以来都在AI领域提供强有力的软件支持。RTX 4090完全兼容CUDA、TensorFlow、PyTorch等主流AI开发框架,使得研究人员和开发者可以无缝地迁移和升级他们的应用程序。此外,NVIDIA还提供了全面的开发者工具和库,如CUDA-X AI库,这些都是为了帮助开发者更有效地利用硬件性能。
其在AI领域中展现出的性能效益比使其成为了性价比极高的选择。对于需要进行大模型推理的企业来说,H100和A100这两种卡虽然性能很好,但是价格过于昂贵,而4090则兼具性能和性价比。
GeForce RTX 4090凭借其强大的性能、大内存容量及较高的性价比,适用于深度学习,渲染、科学计算等场景。虽然性价比出色,但如果普通高校或初创企业想要解决GPU的算力问题,建议还是选择租赁的方式,因为花钱买的话,不仅贵,还会涉及到管理和维护的问题,但租就不存在了。
附高性能NVIDIA RTX 40 系列云服务器购买:
https://www.ucloud.cn/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131083.html
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,而是非常香!直接上图!通过Tensor FP32(TF32)的数据来看,H100性能是全方面碾压4090,但是顶不住H100价格太贵,推理上使用性价比极低。但在和A100的PK中,4090与A100除了在显存和通信上有差异,算力差异与显存相比并不大,而4090是A100价格的1/10,因此如果用在模...

2023年12月28日 英伟达宣布正式发布GeForce RTX 4090D,对比于一年前上市的4090芯片,两者的区别与差异在哪?而在当前比较火热的大模型推理、AI绘画场景方面 两者各自的表现又如何呢?规格与参数信息对比现在先来看看GeForce RTX 4090D到底与之前的GeForce RTX 4090显卡有何区别。(左为4090 右为4090D)从简单的规格来看,GeForce RTX ...

在当今的图形处理领域,NVIDIA一直以其卓越的性能和创新的技术引领市场潮流。作为其最新的旗舰级显卡,GeForce RTX 4090一经发布便吸引了无数玩家的目光。作为最大的卖点,游戏性能以及功效无疑是这张显卡作为佼佼者的地方;于此同时,其关于视频编辑、3D建模、深度学习等专业领域的应用以及广泛的适用性和高效性能同时也是不可忽视的。视频编辑与后期制作RTX 4090不仅仅是一块游戏显卡,它在视频...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采用了NVIDIA的Ampere架构,而H100则是基于Hopper架构。Ampere架构以其高效的图形处理性能和多任务处理能力而...
小模型,成为本周的AI爆点。与动辄上千亿参数的大模型相比,小模型的优势是显而易见的:它们不仅计算成本更低,训练和部署也更为便捷,可以满足计算资源受限、数据安全级别较高的各类场景。因此,在大笔投入大模型训练之余,像 OpenAI、谷歌等科技巨头也在积极训练好用的小模型。先是HuggingFace推出了小模型SmoLLM;OpenAI直接杀入小模型战场,发布了GPT-4o mini。GPT-4o mi...

阅读 12234·2025-03-21 11:44
阅读 594·2025-02-19 18:27
阅读 691·2025-02-19 18:21
阅读 653·2025-02-19 13:50
阅读 1791·2025-02-13 22:35
阅读 1326·2025-02-08 10:20
阅读 5977·2025-01-02 11:25
阅读 1319·2024-12-10 11:51

