
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。
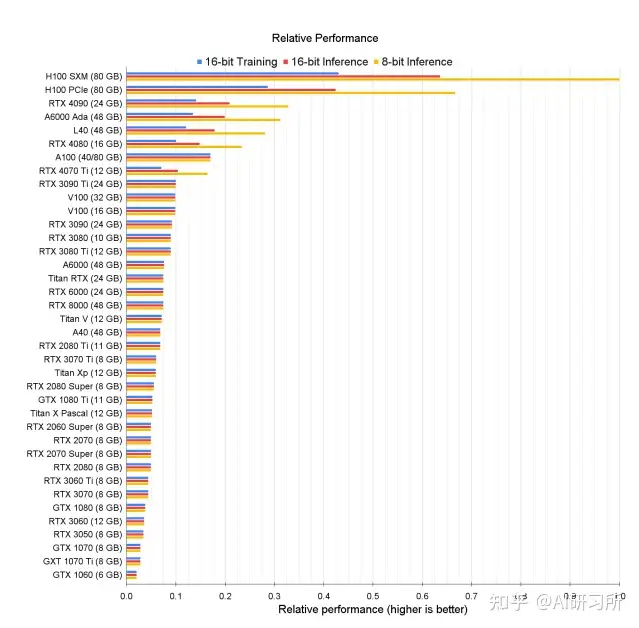
针对大模型训练来说,H100和A100有绝对的优势
首先,从架构角度来看,A100采用了NVIDIA的Ampere架构,而H100则是基于Hopper架构。Ampere架构以其高效的图形处理性能和多任务处理能力而著称,这也是A100在数据中心和AI应用中受到青睐的原因。H100的Hopper架构在A100的基础上进行了优化,使得H100在性能上有了显著的提升,尤其在处理复杂任务和大数据集时表现更为出色。
在性能方面,H100显然占据了上风。其张量核的增强使得在处理AI工作负载时性能大幅提升,达到了A100的六倍之多。这意味着,在进行深度学习训练或推理时,H100能更快地完成任务,提高了整体的工作效率。此外,H100还配备了第五代NVLink,将连接带宽提升到了900GB/秒,使得多卡互联的延迟大幅降低,这对于需要进行大规模并行计算的用户来说无疑是个福音。大模型训练用这两张卡无疑是非常不错的选择。
那么模型推理也是选择H100和A100最合适么?直接给大家看两个案例就明白了。
70B 推理需要多少张卡?
总的存储容量很好算,推理的时候最主要占内存的就是参数、KV Cache 和当前层的中间结果。当 batch size = 8 时,中间结果所需的大小是 batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB,相对来说是很小的。
70B 模型的参数是 140 GB,不管 A100/H100 还是 4090 都是单卡放不下的。那么 2 张 H100 够吗?看起来 160 GB 是够了,但是剩下的 20 GB 如果用来放 KV Cache,要么把 batch size 压缩一半,要么把 token 最大长度压缩一半,听起来是不太明智。因此,至少需要 3 张 H100。
对于 4090,140 GB 参数 + 40 GB KV Cache = 180 GB,每张卡 24 GB,8 张卡刚好可以放下。要知道H100的价格是4090的20倍左右。这个时候4090就非常香了!
针对AI绘画,4090和A100差距如何?
首先,软件用的是SD,模型使用的是SDXL,出图尺寸是888x1280,迭代步数50。A100出一张图花费11.5秒,而4090则略快,只需11.4秒,两者差异较小,但A100表现稍显颓势。
在绘制八张图的情况下,A100耗时87秒,而4090仅用80秒,4090表现出色,领先A100约8%。
总体来说,虽然RTX 4090可能不适合超大规模的AI训练任务,它的强大推理能力使其在大模型的推理应用中显得更为合适。
最最最主要的是,4090性价比高啊!谁家钱是大风刮来的?大家都以一种最经济,高效的方式来做模型推理。这里小编给大家推荐一家性价比非常高的GPU云主机的服务商。
单卡价格做到了1210元,真的太香了,不是H100买不起,而是4090更有性价比!
关键这个活动还是新老同享,续费同价,不用担心续费涨价。
附高性能NVIDIA RTX 40 系列云服务器购买:
https://www.ucloud.cn/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131082.html

(遵循数据全面性、客观性、可验证性及结构化原则)一、排名依据与评估维度本文从以下维度评估GPU云服务器一体机解决方案:性能表现:包括GPU型号覆盖、算力效率、分布式训练支持等。可靠性:服务稳定性、容灾能力、SLA承诺。生态整合:与AI框架的兼容性、多模态大模型支持、开发者工具链。性价比:单位算力成本、弹性计费模式、长期合作折扣。行业适配:企业级服务案例、垂直领域解决方案。二、2025年GPU云服务...
摘要:文章翻译自深度学习是一个计算需求强烈的领域,的选择将从根本上决定你的深度学习研究过程体验。因此,今天就谈谈如何选择一款合适的来进行深度学习的研究。此外,即使深度学习刚刚起步,仍然在持续深入的发展。例如,一个普通的在上的售价约为美元。 文章翻译自:Which GPU(s) to Get for Deep Learning(http://t.cn/R6sZh27)深度学习是一个计算需求强烈的领域...
摘要:在本次竞赛中,南京信息工程大学和帝国理工学院的团队获得了目标检测的最优成绩,最优检测目标数量为平均较精确率为。最后在视频目标检测任务中,帝国理工大学和悉尼大学所组成的团队取得了较佳表现。 在本次 ImageNet 竞赛中,南京信息工程大学和帝国理工学院的团队 BDAT 获得了目标检测的最优成绩,最优检测目标数量为 85、平均较精确率为 0.732227。而在目标定位任务中Momenta和牛津...
摘要:但年月,宣布将在年终止的开发和维护。性能并非最优,为何如此受欢迎粉丝团在过去的几年里,出现了不同的开源深度学习框架,就属于其中典型,由谷歌开发和支持,自然引发了很大的关注。 Keras作者François Chollet刚刚在Twitter贴出一张图片,是近三个月来arXiv上提到的深度学习开源框架排行:TensorFlow排名第一,这个或许并不出意外,Keras排名第二,随后是Caffe、...

阅读 10133·2025-03-21 11:44
阅读 513·2025-02-19 18:27
阅读 566·2025-02-19 18:21
阅读 553·2025-02-19 13:50
阅读 1674·2025-02-13 22:35
阅读 1221·2025-02-08 10:20
阅读 5929·2025-01-02 11:25
阅读 1266·2024-12-10 11:51




