
pg流复制可以是一主多从架构,类似Oracle ADG,都是采用物理复制,从库可提供实时查询业务,流复制在不借助插件的情况下,本身并不提供自动failover等功能。
PGPOOL是一款较流行的Postgres的数据库中间件,提供了连接池、自动故障转移、负载均衡、看门狗等功能。在基于流复制架构下,架构图如下(转自官方文档):
注:本文采用3个主机,进行一主两从架构部署示例。
提前安装好Postgres数据库,并搭建好流复制架构,本文不再做描述。
pgpool最新版本为4.2.2,本文采用4.1.2版作为示例。可选用rpm或者源码包安装,本文采用源码编译的方式安装
安装pgpool_recovery
▼▼▼cd pgpool-II-4.1.2/src/sql/pgpool-recovery
make
make install
psql
c template1
create extension pgpool_recovery;
Installing pgpool-regclass
cd pgpool-II-4.1.2/src/sql/pgpool-regclass
make
make install
psql template1
CREATE EXTENSION pgpool_regclass;
Creating insert_lock table
cd pgpool-II-4.1.2/src/sql
$ psql -f insert_lock.sql template1
修改PG数据库参数文件
pgpool.pg_ctl = /usr/local/postgres/bin/pg_ctl
配置SSH等效性
▼▼▼ssh-keygen -t rsa -f ~/.ssh/id_rsa_pgpool
cd ~/.ssh
ssh-copy-id -i id_rsa_pgpool.pub postgres@host01
ssh-copy-id -i id_rsa_pgpool.pub postgres@host02
ssh-copy-id -i id_rsa_pgpool.pub postgres@host03
ssh postgres@host01 -i ~/.ssh/id_rsa_pgpool
配置Pgpool参数
▼▼▼cp -p /usr/local/pgpool412/etc/pgpool.conf.sample-stream /usr/local/pgpool412/etc/pgpool.conf
##以下为所有节点通用配置
listen_addresses = *
pid_file_name = /usr/local/pgpool412/pgpool.pid
sr_check_user = pgpool
sr_check_password =
health_check_period = 5
health_check_timeout = 30
health_check_user = pgpool
health_check_password =
health_check_max_retries = 3
backend_hostname0 = host01
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = /pgdata
backend_flag0 = ALLOW_TO_FAILOVER
backend_hostname1 = host02
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = /pgdata
backend_flag1 = ALLOW_TO_FAILOVER
backend_hostname2 = host03
backend_port2 = 5432
backend_weight2 = 1
backend_data_directory2 = /pgdata
backend_flag2 = ALLOW_TO_FAILOVER
backend_application_name0 = host01
backend_application_name1 = host02
backend_application_name2 = host03
failover_command = /usr/local/pgpool412/etc/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S
follow_master_command = /usr/local/pgpool412/etc/follow_master.sh %d %h %p %D %m %H %M %P %r %R
recovery_user = postgres
recovery_password =
recovery_1st_stage_command = recovery_1st_stage
enable_pool_hba = on
##看门狗通用配置
use_watchdog = on
delegate_IP = 192.168.56.5
if_cmd_path = /usr/sbin
if_up_cmd = /usr/bin/sudo /usr/sbin/ip addr add $_IP_$/24 dev enp0s3 label enp0s3:0
if_down_cmd = /usr/bin/sudo /usr/sbin/ip addr del $_IP_$/24 dev enp0s3
arping_path = /usr/sbin
arping_cmd = /usr/bin/sudo /usr/sbin/arping -U $_IP_$ -w 1 -I enp0s3
##以下不同主机分别配置
#host02
#host03
#host01
#host02
#host03
#心跳检测相关配置
#host01
#host02
#host03
编辑failover和follow脚本
▼▼▼cd /usr/local/pgpool412/etc/
cp failover.sh.sample failover.sh
cp follow_master.sh.sample follow_master.sh
chmod 755 *.sh
vi failover.sh
PGHOME=/usr/local/postgres
vi follow_master.sh
PGHOME=/usr/local/postgres
ARCHIVEDIR=/pgdata/archivelog
REPLUSER=repl
PCP_USER=pgpool
PGPOOL_PATH=/usr/local/pgpool412
PCP_PORT=9898
配置pcp.conf文件
▼▼▼echo pgpool:`pg_md5 Welcome2021` >> /usr/local/pgpool412/etc/pcp.conf
配置pcppass文件
▼▼▼su - postgres
echo localhost:9898:pgpool:Welcome2021 > ~/.pcppass
chmod 600 ~/.pcppass
配置recover文件 ---这两个文件要放到$PGDATA目录中
▼▼▼cp -p /usr/local/pgpool412/etc/recovery_1st_stage.sample /pgdata/recovery_1st_stage
cp -p /usr/local/pgpool412/etc/pgpool_remote_start.sample /pgdata/pgpool_remote_start
chown postgres:postgres /pgdata/{recovery_1st_stage,pgpool_remote_start}
vi /pgdata/recovery_1st_stage
...
PGHOME=/usr/local/postgres
vi /pgdata/pgpool_remote_start
PGHOME=/usr/local/postgres
chmod 755 {recovery_1st_stage,pgpool_remote_start}
配置pool_hba.conf文件
▼▼▼host all pgpool 0.0.0.0/0 scram-sha-256
host all postgres 0.0.0.0/0 scram-sha-256
配置pgpool密码文件
▼▼▼[all servers]$ pg_enc -m -k ~/.pgpoolkey -u pgpool -p
db password: [pgpool users password]
[all servers]$ pg_enc -m -k ~/.pgpoolkey -u postgres -p
db password: [postgres users passowrd]
# cat /usr/local/pgpool412/etc/pool_passwd
pgpool:AESheq2ZMZjynddMWk5sKP/Rw==
postgres:AESHs/pWL5rtXy2IwuzroHfqg==
为Postgres用户配置sudo权限
vi /etc/sudoers
postgres ALL=(ALL) NOPASSWD: ALL
配置将pgpool日志存放到syslog
▼▼▼vi pgpool.conf
log_destination = syslog
syslog_facility = LOCAL1
mkdir /var/log/pgpool
touch /var/log/pgpool /pgpool.log
vi /etc/rsyslog.conf
...
*.info;mail.none;authpriv.none;cron.none;LOCAL1.none /var/log/messages
LOCAL1.* /var/log/pgpool /pgpool.log
##配置logrotate
vi /etc/logrotate.d/syslog
...
/var/log/messages
/var/log/pgpool/pgpool.log ---新增此行
/var/log/secure
#重启服务
systemctl restart rsyslog
nohup pgpool -D -n & --启动
pgpool -m fast stop --停止
##显示pg节点相关信息
psql -h 10.25.247.99 -p 9999 -U pgpool postgres -c "show pool_nodes"
##pg发生failover并恢复后,show pool_nodes显示状态仍然是down,需要重新attach
pcp_attach_node -h 192.168.56.33 -U pgpool 1
##查看pgpool参数
psql -h 192.168.56.5 -p 9999 -U pgpool postgres -c "pgpool show all" --看所有参数
或者
psql -h 192.168.56.5 -p 9999 -U pgpool postgres -c "pgpool show max_pool " --看指定参数
##查看看门狗节点信息
pcp_watchdog_info -h 10.25.247.99 -U pgpool
上图说明pgpool的主节点是hostname为master的节点,注意的是pgpool的主节点可能跟pg的主节点并不是同一个节点。
###检查pgpool的连接数
pcp_proc_info -U pgpool -h 10.25.247.99 |awk {if (NF==13 && $11==1) print $1,$2,$11,$12}|uniq -c|wc -l
ps -ef|grep pgpool|grep idle|grep -v grep |wc -l
##需注意的参数
num_init_children --指定pgpool可开启的子进程数
max_pool可以缓存的连接数
——注意pgpool最大会产生num_init_children*max_pool个pg数据库连接,所以pg参数max_connections需大于num_init_children*max_pool
reserved_connections --此参数为非0值时,当连接超过num_init_children时,会报错退出,否则连接会被hang住,直到连接数下降可以连接为止
load_balance_mode --开启复制均衡
memory_cache_enabled --是否开启内存缓存
更多精彩干货分享
点击下方名片关注
IT那活儿
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/129905.html
摘要:最近研究了的两种集群方案,分别是和,在这里总结一下二者的机制结构优劣测试结果等。其中的前身的,的前身是。为了避免单点故障,可以为所有节点配置对应的节点。测试测试结果测试结果显示,两种集群与单机的性能指标几乎一致,无法分辨高下。 最近研究了PG的两种集群方案,分别是Pgpool-II和Postgres-XL,在这里总结一下二者的机制、结构、优劣、测试结果等。 1、 Pgpool-I...
摘要:作者谭峰张文升出版日期年月页数页定价元本书特色中国开源软件推进联盟分会特聘专家撰写,国内多位开源数据库专家鼎力推荐。张文升中国开源软件推进联盟分会核心成员之一。 很高兴《PostgreSQL实战》一书终于出版,本书大体上系统总结了笔者 PostgreSQL DBA 职业生涯的经验总结,本书的另一位作者张文升拥有丰富的PostgreSQL运维经验,目前就职于探探科技任首席PostgreS...
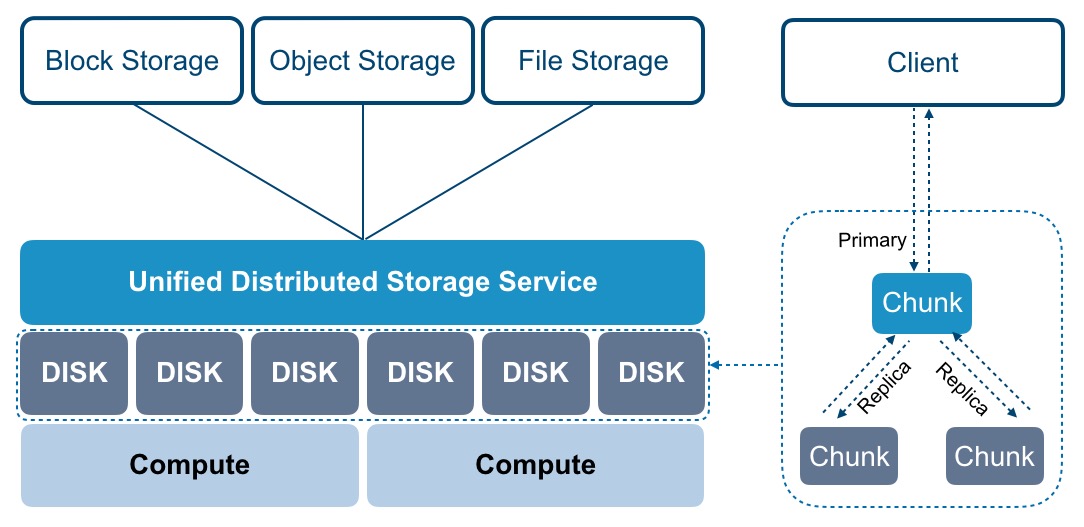
摘要:平台采用分布式存储系统作为虚拟化存储,用于对接虚拟化计算及通用数据存储服务,消除集中式网关,使客户端直接与存储系统进行交互,并以多副本纠删码多级故障域数据重均衡故障数据重建等数据保护机制,确保数据安全性和可用性。云计算平台通过硬件辅助的虚拟化计算技术最大程度上提高资源利用率和业务运维管理的效率,整体降低 IT 基础设施的总拥有成本,并有效提高业务服务的可用性、可靠性及稳定性。在解决计算资源的...
摘要:这可以通过负载平衡来实现数据分片当问题不是并发查询的数量,而是数据库的大小和单个查询的速度时,可以实现不同的方法。 showImg(https://segmentfault.com/img/remote/1460000018875091); 来源 | 愿码(ChainDesk.CN)内容编辑 愿码Slogan | 连接每个程序员的故事 网站 | http://chaindesk.cn...
阅读 1427·2023-01-11 13:20
阅读 1772·2023-01-11 13:20
阅读 1244·2023-01-11 13:20
阅读 1975·2023-01-11 13:20
阅读 4201·2023-01-11 13:20
阅读 2829·2023-01-11 13:20
阅读 1446·2023-01-11 13:20
阅读 3752·2023-01-11 13:20





