分布式数据库TiDB解读
点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
TiDB 是 PingCAP 公司设计的开源分布式数据库,结合了传统的 RDBMS 和 NoSQL 的特性。
TiDB 高度兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。
TIDB具备一整套完整的生态环境,从数据迁移,备份恢复,数据同步,监控告警,HTAP,大数据,运维工具等。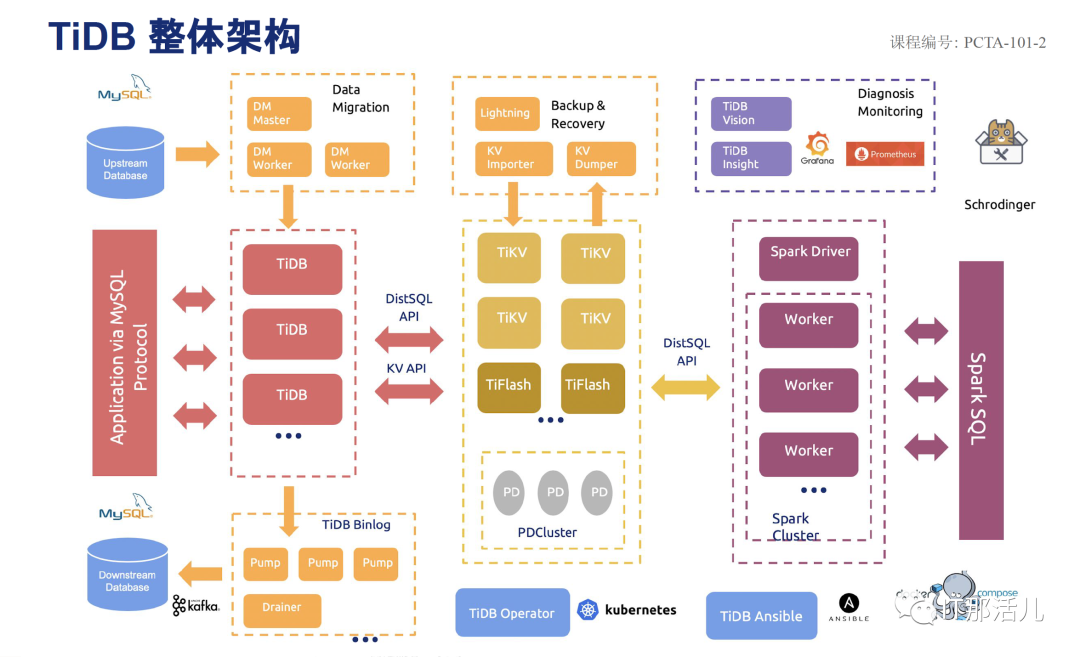
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
TiDB 100% 支持标准的 ACID 事务。
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
- TiDB 是为云而设计的数据库,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
- a: 存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
- b: 对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
PD 不断的通过 Store 或者 Leader 的心跳包收集信息,获得整个集群的详细数据,并且根据这些信息以及调度策略生成调度操作序列,每次收到 Region Leader 发来的心跳包时,PD 都会检查是否有对这个 Region 待进行的操作,通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果。这里的操作只是给 Region Leader 的建议,并不保证一定能得到执行,具体是否会执行以及什么时候执行,由 Region Leader 自己根据当前自身状态来定。调度依赖于整个集群信息的收集,需要知道每个TiKV节点的状态以及每个Region的状态。TiKV集群会向PD汇报两类信息:1)每个TiKV节点会定期向PD汇报节点的整体信息。TiKV节点(Store)与PD之间存在心跳包,一方面PD通过心跳包检测每个Store是否存活,以及是否有新加入的Store;另一方面,心跳包中也会携带这个Store的状态信息,主要包括: e) 发送/接受的Snapshot数量(Replica之间可能会通过Snapshot同步数据) g) 标签信息(标签是否具备层级关系的一系列Tag)2)每个 Raft Group 的 Leader 会定期向 PD 汇报Region信息每个Raft Group 的 Leader 和 PD 之间存在心跳包,用于汇报这个Region的状态,主要包括下面几点信息:
PD 不断的通过这两类心跳消息收集整个集群的信息,再以这些信息作为决策的依据。
除此之外,PD 还可以通过管理接口接受额外的信息,用来做更准确的决策。比如当某个 Store 的心跳包中断的时候,PD 并不能判断这个节点是临时失效还是永久失效,只能经过一段时间的等待(默认是 30 分钟),如果一直没有心跳包,就认为是 Store 已经下线,再决定需要将这个 Store 上面的 Region 都调度走。但是有的时候,是运维人员主动将某台机器下线,这个时候,可以通过 PD 的管理接口通知 PD 该 Store 不可用,PD 就可以马上判断需要将这个 Store 上面的 Region 都调度走。TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址, 与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展, 可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。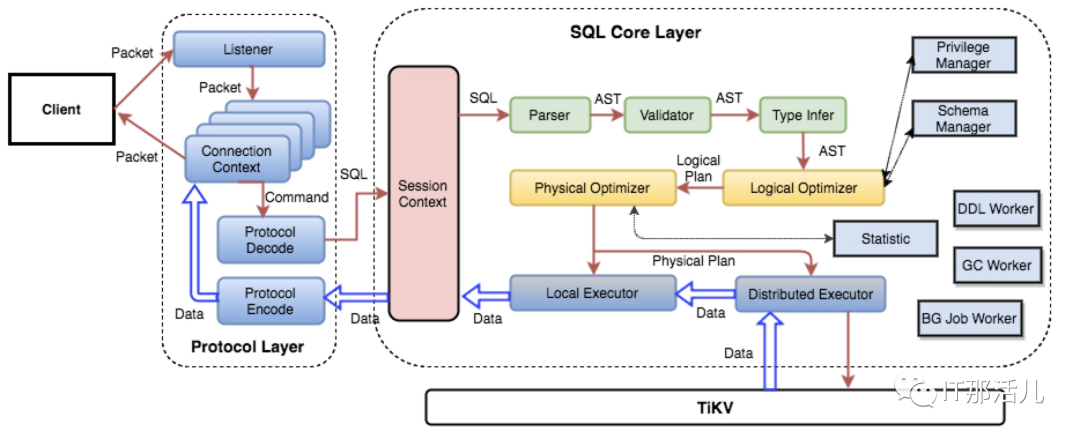 SQL引擎TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region, 每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据, 每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。TiKV单节点选择了基于LSM-tree的RocksDB引擎,底层使用kv存储结构,没有使用btree,而是采用lsm-tree的索引结构(log structured merge trees)
SQL引擎TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region, 每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据, 每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。TiKV单节点选择了基于LSM-tree的RocksDB引擎,底层使用kv存储结构,没有使用btree,而是采用lsm-tree的索引结构(log structured merge trees)- LMS-tree:是一个用空间置换写入演出,用顺序写入替换随机写入的数据结构。
- 当收到一个写请求时,会先把该条数据记录在WAL Log里面,用作故障恢复。
- 当写完WAL Log后,会把该条数据写入内存的SSTable里面(删除是墓碑标记,更新是新记录一条的数据),也称Memtable。注意为了维持有序性在内存里面可以采用红黑树或者跳跃表相关的数据结构。
- 当Memtable超过一定的大小后,会在内存里面冻结,变成不可变的Memtable,同时为了不阻塞写操作需要新生成一个Memtable继续提供服务。
- 把内存里面不可变的Memtable给dump到到硬盘上的SSTable层中,此步骤也称为Minor Compaction,这里需要注意在L0层的SSTable是没有进行合并的,所以这里的key range在多个SSTable中可能会出现重叠,在层数大于0层之后的SSTable,不存在重叠key。
- 当每层的磁盘上的SSTable的体积超过一定的大小或者个数,也会周期的进行合并。此步骤也称为Major Compaction,这个阶段会真正 的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于SSTable都是有序的,我们可以直接采用merge sort进行高效合并。
选择了基于LSM-tree的RocksDB引擎,底层使用kv存储结构,没有使用B-tree,而是采用LMS-tree的索引结构(log structured merge trees)RocksDB存储引擎,RockDB 性能很好但是是单机的,为了保证高可用所以写多份,上层使用 Raft 协议来保证单机失效后数据不丢失不出错。保证有了比较安全的 KV 存储的基础上再去构建多版本,再去构建分布式事务,这样就构成了存储层 TiKV。RocksDB特点:
a) RocksDB是一款非常成熟的lms-tree引擎;采用Raft复制协议,TiKV采用range分片算法。- raft是一种用于替代paxos的共识算法相比于paxos,raft的目标是提供更清晰的逻辑分工使得算法本身能被更好的理解,同时它的安全性更高,并能提供一些额外的特性。
TiFlash是4.0版本引入的新特性,TiFlash以Raft Learner方式接入Multi-Raft组,使用异步方式传输数据,对TiKV产生非常小的负担;当数据同步到TiFlash时,会被从行格式解析为列格式。 TiDB提供基于Prometheus+Grafana和Dashboard两种监控方式,Prometheus方式可以提供告警,Dashboard方式不能提供报警。
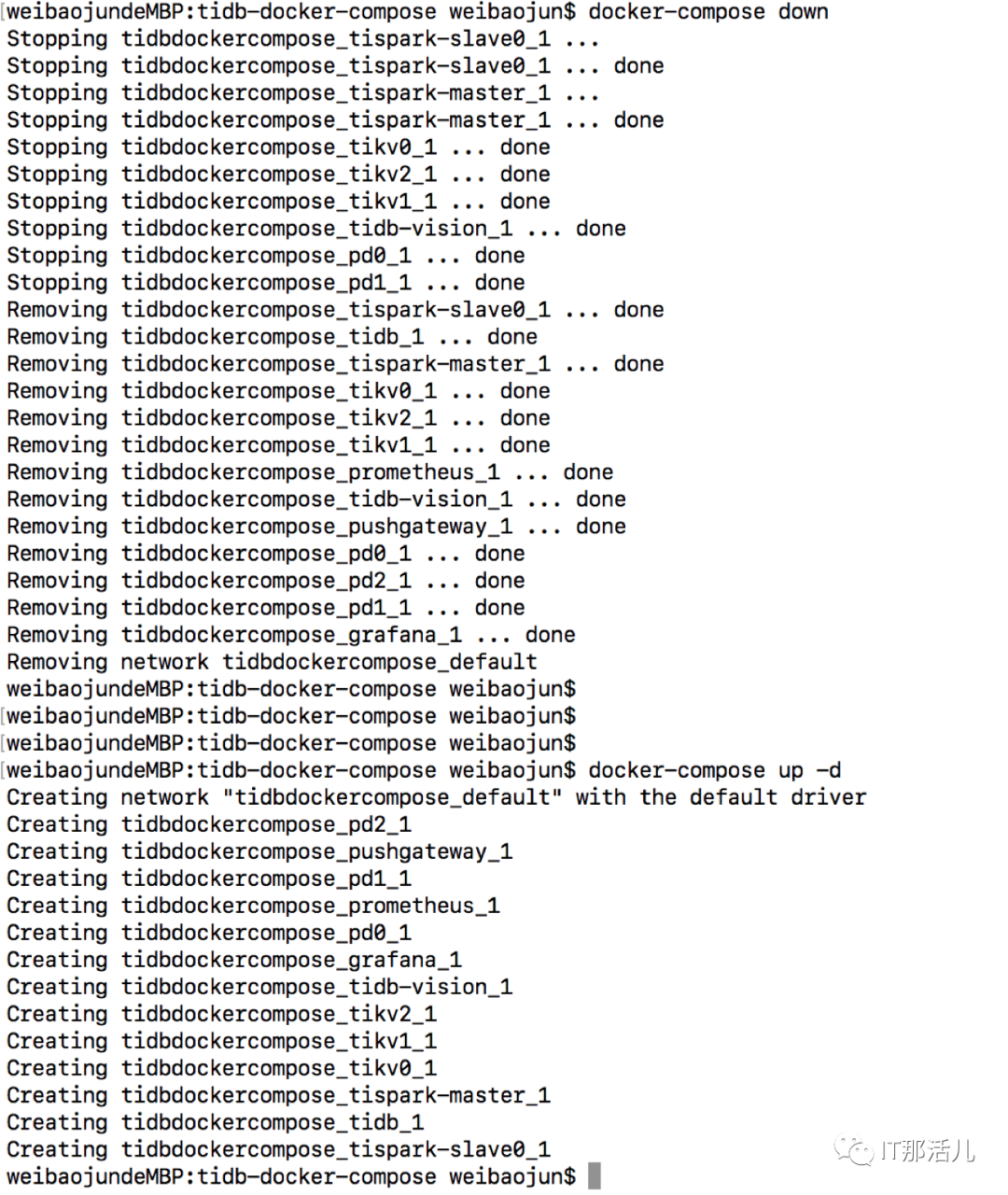
3.1 下载tidb-docker-compose查看集群配置文件cat docker-compose.yml (3个PD,3个tikv,1个tidb以及其他组prometheus,grafana,tidb-vision,spark)TiDB启动顺序:PD -> TiKV -> TiDB -> TiFlash,关闭顺序正好相反。docker-compose down
docker-compose up -d
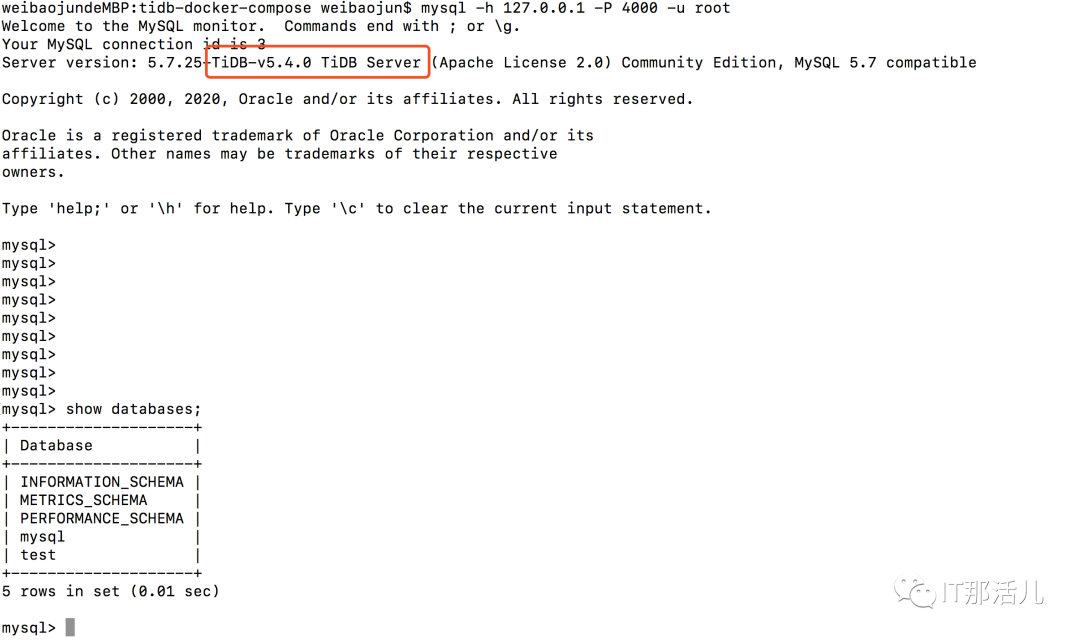
原因:TiKV 启动时预占额外空间的临时文件大。临时文件名为 space_placeholder_file,位于 storage.data-dir 目录下。TiKV 磁盘空间耗尽无法正常启动需要紧急干预时,可以删除该文件,并且将 reserve-space 设置为 0MB。默认5GB。mysql -h XXX.0.0.1 -P 4000 -u root

文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/129366.html





