
OLAP 的查询一般需要 Scan 大量数据,大多时候只访问部分列,聚合的需求(Sum,Count,Max,Min 等)会多于明细的需求(查询原始的明细数据)。
OLAP分类:
doris是一个ROLAP引擎, 可以满足以下需求:
Doris的架构很简洁,使用MySQL协议,用户可以使用任何MySQL ODBC/JDBC和MySQL客户端直接访问Doris,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。
数据的可靠性由BE保证,BE会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
step1 拉取Doris官方提供的Docker镜像,目前可用版本有:build-env、build-env-1.1、build-env-1.2
docker pull apachedoris/doris-dev:build-env-1.2step2 查看 Docker 镜像
docker imagesstep3 运行镜像
将容器中的 maven 下载的包保存到宿主机本地指定的文件中,避免重复下载,同时会将编译的 Doris 文件保存到宿主机本地指定的文件,方便部署。
docker run -it
-v /u01/.m2:/root/.m2
-v /u01/incubator-doris-DORIS-0.13-release/:/root/incubator-doris-DORIS-0.13-release/
apachedoris/doris-dev:build-env-1.2开启之后, 就在容器内了。
tar -zxvf apache-doris-0.13.0.0-incubating-src.tar.gz
cd apache-doris-0.13.0.0-incubating-srcsh build.sh编译完成。
注意点二:FE 节点的数量
网络需求:
Doris 各个实例直接通过网络进行通讯。以下表格展示了所有需要的端口。
vim /etc/profile#DORIS_HOME
export DORIS_HOME=/export/server/apache-doris-0.13.0
export PATH=:$DORIS_HOME/bin:$PATH3)重新加载环境变量
source /etc/profilemkdir -p /export/server/apache-doris-0.13.0/fe/doris-metavim conf/fe.confmeta_dir = /export/server/apache-doris-0.13.0/fe/doris-metavim /export/server/apache-doris-0.13.0/fe/conf/fe.confpriority_networks = ip/24sh /export/server/apache-doris-0.13.0/fe/bin/start_fe.sh --daemon将源码编译生成的 output 下的 be 文件夹拷贝到 BE 的节点/export/server/apache-doris-0.13.0路径下:
配置文件为 be/conf/be.conf。主要是配置 storage_root_path:数据存放目录。默认在be/storage下,需要手动创建该目录。多个路径之间使用 ; 分隔(最后一个目录后不要加 ;)
mkdir -p /export/server/apache-doris-0.13.0/be/storage1 /export/server/apache-doris-0.13.0/be/storage2
vim conf/be.conf
storage_root_path = /export/server/apache-doris-0.13.0/be/storage1,10;/export/server/apache-doris-0.13.0/be/storage2
step1 删除操作系统自带的mysql库文件(node1)
rpm -qa | grep mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64step2 安装mysql-client
上传”资料软件mysql-client”目录下的rpm到服务器节点/export/server/mysql-client.
step3 进行安装
rpm -ivh *step4 连接node1服务器上的mysql实例(默认端口9030,默认没有密码)
mysql -uroot -h node1 -P 9030step5 登陆后,可以通过以下命令修改 root 密码
SET PASSWORD FOR root = PASSWORD(123456);step6 使用Navicat客户端登录
step1 BE 节点需要先在 FE 中添加,才可加入集群(node1)
mysql -uroot -h node1 -P 9030 -p输入密码:123456
step2 登录后添加BE节点port为be上的heartbeat_service_port端口,默认9050
ALTER SYSTEM ADD BACKEND "node1:9050";
ALTER SYSTEM ADD BACKEND "node2:9050";
ALTER SYSTEM ADD BACKEND "node3:9050";step3 查看BE状态,alive必须为true
SHOW PROC /backends;查看 BE 运行情况。如一切正常,isAlive 列应为 true。
ulimit -n 65535vim /export/server/apache-doris-0.13.0/be/conf/be.conf
priority_networks = ip/24sh /export/server/apache-doris-0.13.0/be/bin/start_be.sh --daemonshow proc /frontends;show proc /backends;通过前端界面访问FE:
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/129229.html
摘要:近日,全球著名开源社区基金会宣布百度开源的项目全票通过进入孵化器。这是百度继后第二个进入基金会的项目,充分彰显了百度开源速度。前身是百度,自年月在上开源以来,收获多个,目前性能和易用性方面已达到业界领先水平。 近日,全球著名开源社区Apache基金会宣布百度开源的Doris项目全票通过进入Apache孵化器。这是百度继ECharts后第二个进入Apache基金会的项目,充分彰显了百度开...

摘要:如何连接云数据仓库如何连接云数据仓库如何连接云数据仓库为保证安全,云数据仓库仅提供内网网络,您连接集群时可以配合同一地域的云主机或者网络产品使用。 产品购买与使用本篇目录为什么只提供一种云盘类型?配置升降级对集群有什么影响?配置升级有什么建议?如何连接云数据仓库UDoris?为什么只提供一种云盘类型?Doris的存储特性对磁盘吞吐量要求很高,为保证Doris的性能优势, 因此仅提供RSSD云...
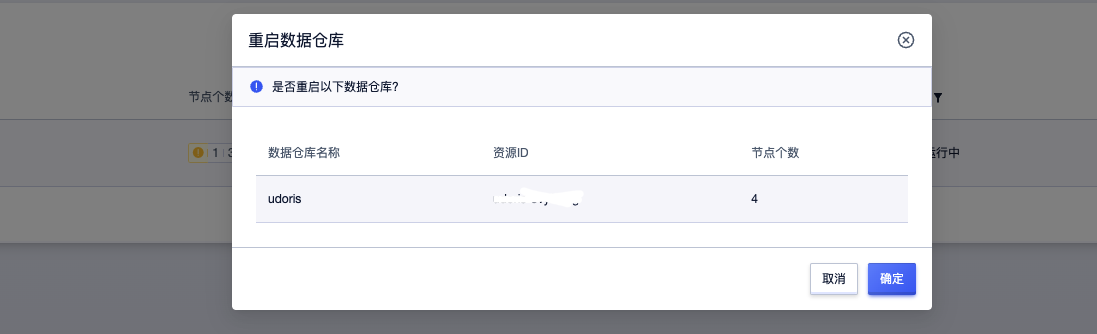
摘要:重启集群重启集群重启集群当您需要重启集群时,登录账号进入到用户控制台,在全部产品下搜索或者数据仓库下选择数据仓库,进入到数据仓库控制台下,选择操作重启注意重启集群为高危操作,集群将处于重启中持续数秒,建议无必要时不要随意重启实例,这将会 重启集群当您需要重启集群时,登录UCloud账号进入到用户控制台,在全部产品下搜索或者数据仓库下选择数据仓库 UDW Doris,进入到数据仓库UDoris...
摘要:数据排序使用的列数,取最前面几列,不能超过总的列数。示例创建一个动态分区表。创建外部表创建外部表在创建外部表的目的是可以通过访问外部数据库。创建表时,关于和的数量和数据量的建议。 建表(Create Table)创建表语法:CREATE TABLE [IF NOT EXISTS] [database.]table ( column_definition_list, [inde...
摘要:概览概览概览产品动态产品介绍什么是云数据仓库产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级节点扩容重启实例重置管理员密码删除集群连接集群数据导入本地数据导入数据导入通过导入开发指南数据类型语法创建库创建表创建视图插入数 概览概览产品动态产品介绍什么是云数据仓库UDoris产品优势应用场景基本概念使用限制快速上手操作指南管理集群Backend配置升降级Frontend节点扩...
阅读 1493·2023-01-11 13:20
阅读 1853·2023-01-11 13:20
阅读 1290·2023-01-11 13:20
阅读 2042·2023-01-11 13:20
阅读 4244·2023-01-11 13:20
阅读 2958·2023-01-11 13:20
阅读 1583·2023-01-11 13:20
阅读 3857·2023-01-11 13:20



