从故障自愈看稳定性保障体系
点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
故障自愈是指实时发现告警,预诊断分析,自动恢复故障,并打通周边系统实现故障的快速恢复。故障自愈在是稳定性保障能力中是重要的一环,在稳定性保障体系中主要是通过自动化、半自动化的手段对执行故障预案对故障修复,提升MTTR,并通过故障复盘来降低MTTF。今天笔者想从故障自愈的角度入手去聊下故障的处理流程,这里包含简单的处理预案的告警自愈,有告警快照获取并进行自动化自愈的故障自愈,也有站在整个故障的角度对故障进行协同处理的故障处理流程。故障自愈主要是分为两种:一种是消极的故障自愈,另一个是积极的故障自愈。本文可能涉及到一些协作平台的介绍,当然这里的协作都是指的运维协作。
随着各领域数字化转型的推进,信息系统的应用范围不断扩大、 承载业务愈发关键,用户的高频访问成为常态。面对业务的需求,IT技术也在不断的演进,IT开始走向分布式,而近几年分布式其实发生了很多的变化,从最早的10年11年的时候,可能大家熟悉的SOA甚至在之前EJB,然后到后来的这种微服务, Dubbo、Spring Cloud,然后到容器,再到现在的kubernetes的云原生,甚至到可以那个时候说是Service Mesh,那么系统实际上被越来越多的变成无状态的,越来越多的变成分布式的。系统变得越来越庞大,随之给系统的稳定性带来了巨大的挑战。
稳定性保障体系演进过程
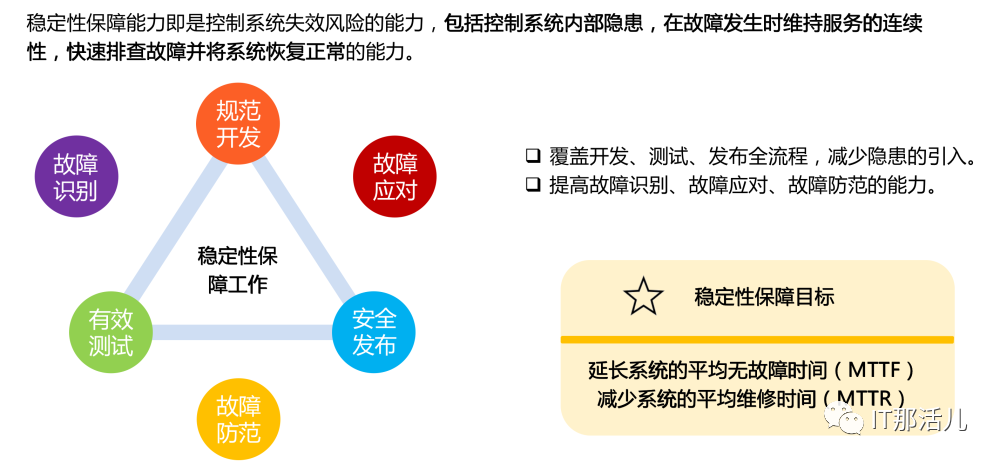
稳定性保障能力
消极自愈
消极自愈治标不治本,例如磁盘告警后的自动清理和扩容,只要产生相关告警直接进行磁盘扩容或清理。第一种是全消极自愈,当监控平台出现告警之后直接调用自动化平台的操作去做执行脚本进行恢复,其实这种严格来说是一种消极的故障自愈,也没有什么故障的根因分析,一旦出现问题直接上三板斧(重启、关机、切流)或者是直接执行告警恢复预案。如果执行不了预案就只能进行人工处理直至进行问题闭环。这种自愈主要面向的是一些数据库杀锁、文件清理、中间件/数据库DOWN等简单的场景。第二种半消极自愈,这个半消极自愈是笔者的自己理解,所谓的半消极自愈说的是在执行自愈预案之前先进行故障快照的抓取,保留一部分故障现场。当然这里还有层意思是说有些故障告警是单一脚本无法进行恢复,需要脚本、API接口、人工判断,通过流程引擎将这几个对象进行串联或者并联,甚至将上一个操作的结果输出到下一个结果来完成一系列的自愈流程来进行故障处理。如下图是一个简单的自动故障处理流程,告警触发之后匹配处理策略,如果匹配成功就进行故障快照抓取脚本,再去执行脚本动作1再到脚本动作2,这可能涉及到去调用业务系统的API接口然后触发一个合流的动作,将两个API调用的结果合并在一起输出至另一个脚本进行执行,最后需要人工确认是否故障处理完成,人工判断确认执行点击通过结束故障处理流程。
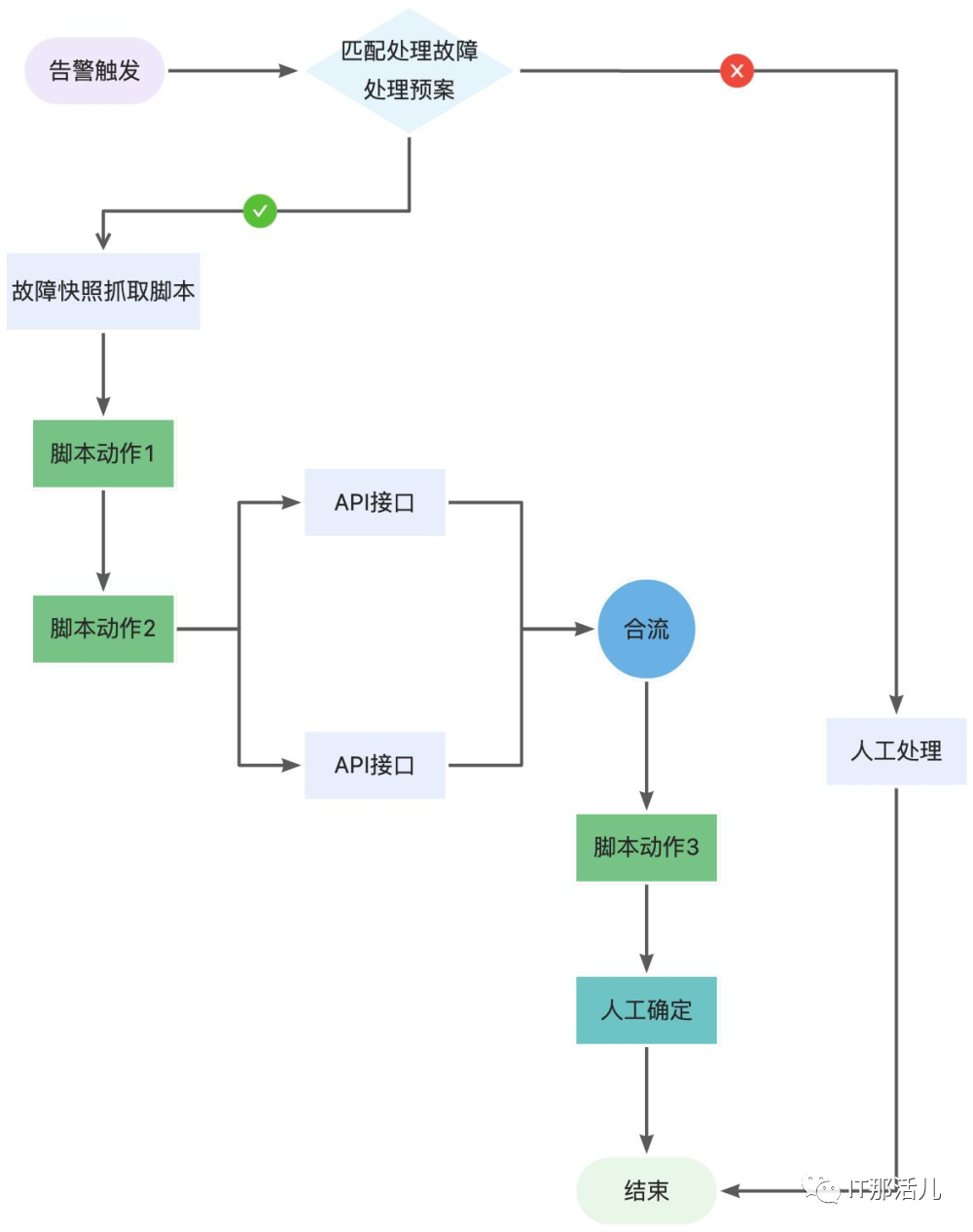 上面的流程可能看起来有些复杂,但是在现网出现的故障是有这种情况出现的,这里传达了一个思想,一个故障的处理流程可能不仅仅只是调用python、shell脚本进行故障的处理,可能还需要去调用业务系统的一些接口,最终还需要进行人工确认是否已解决此故障来完成这个故障的自愈。
上面的流程可能看起来有些复杂,但是在现网出现的故障是有这种情况出现的,这里传达了一个思想,一个故障的处理流程可能不仅仅只是调用python、shell脚本进行故障的处理,可能还需要去调用业务系统的一些接口,最终还需要进行人工确认是否已解决此故障来完成这个故障的自愈。积极自愈
积极的故障自愈,就是在进行故障自愈的过程中要对故障根因进行分析,当然这种故障也包含了很复杂的故障处理流程,可能需要拉通各种的运维工具,以及需要调动不同的专业组的人进行一起协同处理故障,像这种告警是一个流程化的工程,首先是触发一个工单(类似的故障可能不能第一时间对故障进行服务)去跟进这个故障推动他闭环,第二是需要人工判断使用那些脚本,执行什么样的操作去进行告警恢复。
为什么不是ITSM?
不管是消极自愈还是积极自愈,在整个流程过程中都有提到一个概念是流程,不管是简单的还是无法直接自愈的操作都是需要一个强大的流程引擎对故障进行恢复。流程引擎一般都是业务系统中使用的,几乎每个业务系统都有自己的内部流程,像OA、CRM等这些系统强流程化的。当然运维行业中管理侧的系统---ITSM系统,也是一个强流程的运维管理系统。ITSM是通过流程去驱动运维工作线上化,推动事件、问题的闭环,对请求、变更、发布等流程的记录,做到事后跟踪和复盘。有些人就说是不是可以使用ITSM的流程引擎去实现不同对象之间的操作。当然ITSM的流程引擎是可以处理这些流程,但是ITSM天生就是用来调用角色、人等的操作,它的出现是为了让运维工作流程化、线上化,并通过管理来将运维流程线上化,因此ITSM主要是用于运维流程和标准化管理。运维任务协同
那我们需要的运维流程引擎是一个什么样的东西呢,这里与其说是运维流程引擎,不如说是运维任务协同平台,是一个可以连接人、 ITOM 工具、运维操作、业务应用API,以及通过调动ITSM的服务目录将背后一系列的动作和跨平台的不同任务,利用运维任务协同平台串联起来,用以提供顺畅、标准化的 IT 运维服务体验,并从 IT 运营视角得到的数据为运维和应急保障提供指导。有了这个既可以调动人、运维操作、ITOM工具、业务应用API等的运维任务协同平台,我们就可以重新定义一些运维工作和任务。通过运维任务协同平台将定义运维流程和管理ITSM、IT资产管理的ITOM、运维工作的参与者、涉及的业务系统、运维操作,拉通在一个轨道上进行不同的任务协作,最终构建统一的运维协作中心。业界成功经验---Service Now
这里以业界著名的ITSM厂商Service Now为案例,ServiceNow创立于2004年,Service Now的愿景在于借助IT工具,实现企业工作流的创建、编排和自动化管理等,以简化和代替企业的事务型工作。Service Now拥有全球最为优秀的工作流引擎,依托这个强大的工作流引擎Service Now从ITSM 业务起步,不断的“开花散叶”,目前业务已经实现了ITOM、人力资源管理、客户服务管理、安全运营管理等不同的领域的跨界。从Service Now的实践中我们可以总结出来,上文提到的运维任务协同平台和Service Now的流程引擎是一样的东西,Service Now借助它的流程引擎开出了ITSM这朵让同行望尘莫及的“花”,同理当我们拥有了运维任务协同平台之后,可以依托此拉通不同的运维任务,开出更多的“花”,甚至可以长出一棵参天大树。
前文有提到积极的故障自愈是在自愈的过程中既要推动执行故障预案,还要去分析故障的根因。下面聊的积极自愈是一个复杂的不能通过简单的流程快速处理的故障,这种故障可能不仅仅需要告警出现之后去关联知识库,还需要去关联可观测性平台的一些指标去进行关联,以及拉起一个协作空间快速的处理故障,最后推动故障复盘。流程如下图: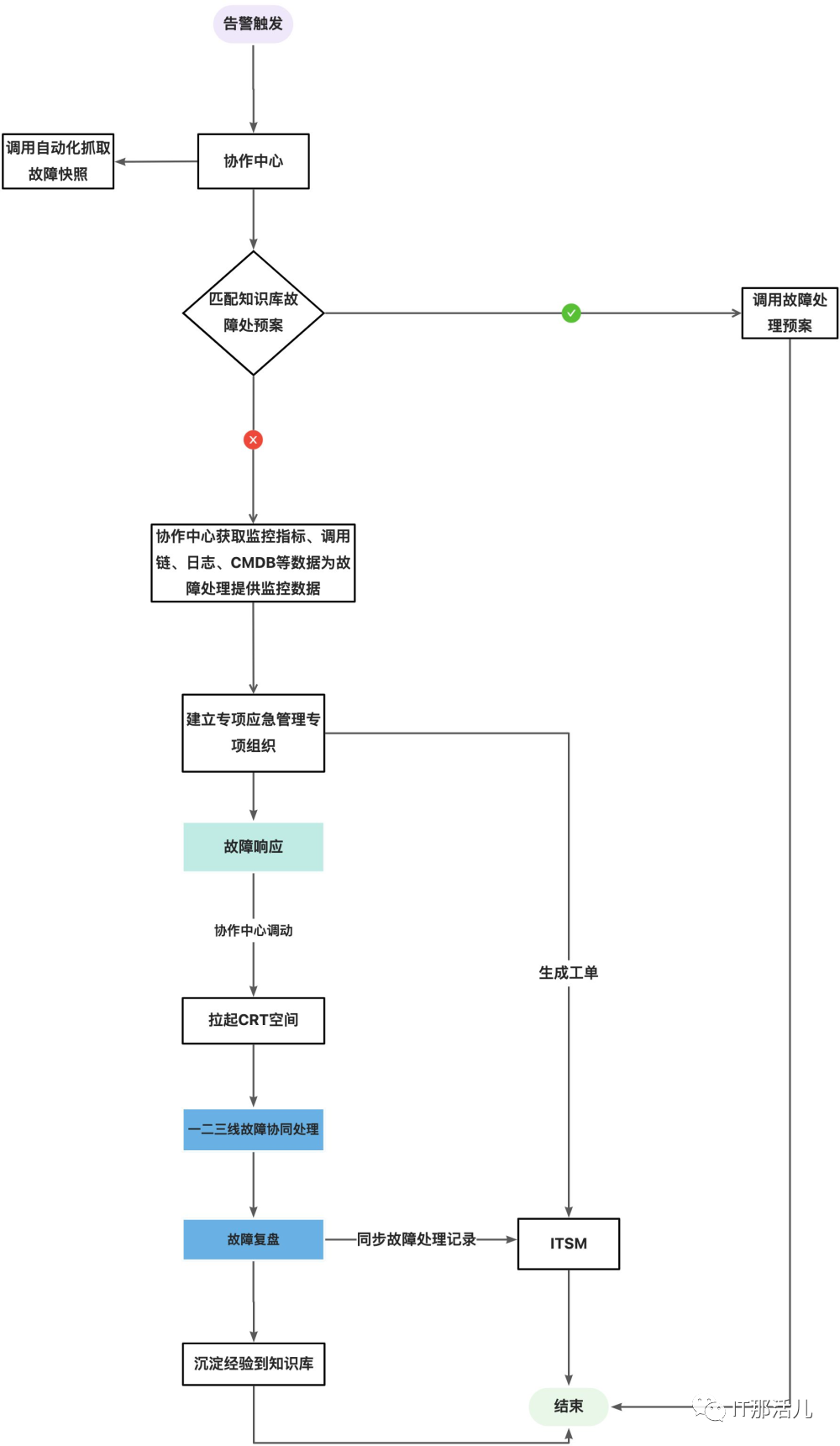 当故障触发的时候,协作中心会去调用自动化执行平台去抓取相关的故障快照;同时会去知识库匹配处理经验,如果匹配成功将调用自动化平台的执行或者是其他的流程完成故障自愈。如果没有在知识库中匹配到故障处理经验,协作中心会去查询CMDB(或可观测性平台)的故障影响范围,并基于CMDB中相关资产维护人拉起一个专项的应急管理组织去处理组织,通过还会生成一个事件单或者是故障单同步至ITSM平台(故障管理平台)。通过建立的故障处理组织,首先就对故障进行响应进行处理故障。在故障响应之后会通过协作中心拉起一个协同的处理空间,这个空间使大家在一个纬度去处理故障,空间里边会汇聚监控指标、调用链、日志、CMDB资产关联关系、历史告警等信息,并能看到故障开始到当前的处理过程,当然还需要一个工具是让一二三线工程师可以看到后续的操作步骤,并可以随时介入进行故障的处理,在这里我们把这个工具定义为在线CRT,它的作用主要是可以让组织空间里边的人可以同时看到当前故障处理过程中实时执行的命令,也要具备当一线解决不了的时候可以通过转移转给二线或三线处理。故障处理完成之后协作中心会去发起一个故障复盘,去反问故障原因有哪些?我们做什么,怎么做才能确保下次不会再出现类似故障?当时如果我们做了什么,可以用更短的时间恢复业务?故障复盘完成,将回答的故障三问固化到知识库,同步将其推送至ITSM进行故障闭环。
当故障触发的时候,协作中心会去调用自动化执行平台去抓取相关的故障快照;同时会去知识库匹配处理经验,如果匹配成功将调用自动化平台的执行或者是其他的流程完成故障自愈。如果没有在知识库中匹配到故障处理经验,协作中心会去查询CMDB(或可观测性平台)的故障影响范围,并基于CMDB中相关资产维护人拉起一个专项的应急管理组织去处理组织,通过还会生成一个事件单或者是故障单同步至ITSM平台(故障管理平台)。通过建立的故障处理组织,首先就对故障进行响应进行处理故障。在故障响应之后会通过协作中心拉起一个协同的处理空间,这个空间使大家在一个纬度去处理故障,空间里边会汇聚监控指标、调用链、日志、CMDB资产关联关系、历史告警等信息,并能看到故障开始到当前的处理过程,当然还需要一个工具是让一二三线工程师可以看到后续的操作步骤,并可以随时介入进行故障的处理,在这里我们把这个工具定义为在线CRT,它的作用主要是可以让组织空间里边的人可以同时看到当前故障处理过程中实时执行的命令,也要具备当一线解决不了的时候可以通过转移转给二线或三线处理。故障处理完成之后协作中心会去发起一个故障复盘,去反问故障原因有哪些?我们做什么,怎么做才能确保下次不会再出现类似故障?当时如果我们做了什么,可以用更短的时间恢复业务?故障复盘完成,将回答的故障三问固化到知识库,同步将其推送至ITSM进行故障闭环。结 语
上面介绍的故障处理流程可能非常长,在真实环境中肯定是以恢复故障为主,流程看似很长,其实通过运维协作中心串联起来之后就会很快的去流转起来,推动整个流程的闭环。本文主要是介绍的故障处理的过程,也掺杂了一点故障复盘的东西,真实的故障管理是包括故障等级定义(有些告警是不能作为故障的,笔者认为只有影响到整个业务系统缓慢、卡顿、hang的告警才能判定为故障)、故障发现、故障响应、故障应急、故障恢复、故障复盘及持续改进。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/129214.html






