TIDB运维文档(下)
点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
接上篇《TiDB运维文档(上)》,我们今天讲一下TIDB数据库的日常运维。
1.1 升级 TiUP 或更新 TiUP 离线镜像
1.2 检查当前集群的健康状况
执行结束后,最后会输出 region status 检查结果。
如果结果为 "All regions are healthy",则说明当前集群中所有 region 均为健康状态,可以继续执行升级;
如果结果为 "Regions are not fully healthy: m miss-peer, n pending-peer" 并提示 "Please fix unhealthy regions before other operations.",则说明当前集群中有 region 处在异常状态,应先排除相应异常状态,并再次检查结果为 "All regions are healthy" 后再继续升级。
1.3 升级 TiDB 集群
TiUP Cluster 默认的升级 TiDB 集群的方式是不停机升级,即升级过程中集群仍然可以对外提供服务。升级时会对各节点逐个迁移 leader 后再升级和重启,因此对于大规模集群需要较长时间才能完成整个升级操作。如果业务有维护窗口可供数据库停机维护,则可以使用停机升级的方式快速进行升级操作。tiup cluster upgrade <cluster-name> v5.1.2
注意:
2.1 扩容 TiDB/PD/TiKV 节点
2.1.1 在 scale-out.yaml 文件添加扩容拓扑配置
tidb_servers:
- host: 10.0.1.5
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: /data/deploy/install/deploy/tidb-4000
log_dir: /data/deploy/install/log/tidb-4000
tikv_servers:
- host: 10.0.1.5
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/deploy/install/deploy/tikv-20160
data_dir: /data/deploy/install/data/tikv-20160
log_dir: /data/deploy/install/log/tikv-20160
pd_servers:
- host: 10.0.1.5
ssh_port: 22
name: pd-1
client_port: 2379
peer_port: 2380
deploy_dir: /data/deploy/install/deploy/pd-2379
data_dir: /data/deploy/install/data/pd-2379
log_dir: /data/deploy/install/log/pd-2379
可以使用 tiup cluster edit-config 查看当前集群的配置信息,因为其中的 global 和 server_configs 参数配置默认会被 scale-out.yaml 继承,因此也会在 scale-out.yaml 中生效。2.1.2 执行扩容命令
tiup cluster scale-out scale-out.yaml
预期输出 Scaled cluster out successfully 信息,表示扩容操作成功。2.2 扩容 TiFlash 节点
2.2.1 添加节点信息到 scale-out.yaml 文件
编写 scale-out.yaml 文件,添加该 TiFlash 节点信息(目前只支持 ip,不支持域名):tiflash_servers:
- host: 10.0.1.4
2.2.2 运行扩容命令
tiup cluster scaltiup cluster scale-out
scale-out.yamle-out scale-out.yaml
2.3 扩容 TiCDC 节点
2.3.1 添加节点信息到 scale-out.yaml 文件
cdc_servers:
- host: 10.0.1.3
- host: 10.0.1.4
2.3.2 运行扩容命令
tiup cluster scale-out scale-out.yaml
2.4 缩容 TiDB/PD/TiKV 节点
2.4.1 查看节点 ID 信息
2.4.2 执行缩容操作
tiup cluster scale-in <cluster-name> --node 10.0.1.5:20160
预期输出 Scaled cluster in successfully 信息,表示缩容操作成功。2.4.3 检查集群状态
下线需要一定时间,下线节点的状态变为 Tombstone 就说明下线成功。2.5.1 根据 TiFlash 剩余节点数调整数据表的副本数
在下线节点之前,确保 TiFlash 集群剩余节点数大于等于所有数据表的最大副本数,否则需要修改相关表的 TiFlash 副本数。在 TiDB 客户端中针对所有副本数大于集群剩余 TiFlash 节点数的表执行:alter table name>.<table-name> set tiflash replica 0;
等待相关表的 TiFlash 副本被删除(按照查看表同步进度一节操作,查不到相关表的同步信息时即为副本被删除)。2.5.2 执行缩容操作
执行 scale-in 命令来下线节点,假设步骤 1 中获得该节点名为 10.0.1.4:9000tiup cluster scale-in <cluster-name> --node 10.0.1.4:9000
2.6 缩容 TiCDC 节点
tiup cluster scale-in <cluster-name> --node 10.0.1.4:8300
3.1 BR备份恢复
BR 全称为 Backup & Restore,是 TiDB 分布式备份恢复的命令行工具,用于对 TiDB 集群进行数据备份和恢复。BR 只支持在 TiDB v3.1 及以上版本使用。 BR 将备份或恢复操作命令下发到各个 TiKV 节点。TiKV 收到命令后执行相应的备份或恢复操作。此备份只备份各节点的leader副本。 在一次备份或恢复中,各个 TiKV 节点都会有一个对应的备份路径,TiKV 备份时产生的备份文件将会保存在该路径下,恢复时也会从该路径读取相应的备份文件。备份路径下会生成以下几种类型文件:
- SST 文件:存储 TiKV 备份下来的数据信息。
- backupmeta 文件:存储本次备份的元信息,包括备份文件数、备份文件的 Key 区间、备份文件大小和备份文件 Hash (sha256) 值。
- backup.lock 文件:用于防止多次备份到同一目录。
1) 推荐部署配置
推荐使用一块高性能 SSD 网盘,挂载到 BR 节点和所有 TiKV 节点上,网盘推荐万兆网卡,否则带宽有可能成为备份恢复时的性能瓶颈。2) 备份数据
br backup full
--pd "${PDIP}:2379"
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backupfull.log
以上命令中,--ratelimit 选项限制了每个 TiKV 执行备份任务的速度上限(单位 MiB/s)。--log-file 选项指定把 BR 的 log 写到 backupfull.log 文件中。br backup db
--pd "${PDIP}:2379"
--db test
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backuptable.log
db 子命令的选项为 --db,用来指定数据库名。其他选项的含义与备份全部集群数据相同。br backup table
--pd "${PDIP}:2379"
--db test
--table usertable
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backuptable.log
table 子命令有 --db 和 --table 两个选项,分别用来指定数据库名和表名。其他选项的含义与备份全部集群数据相同。如果你需要以更复杂的过滤条件来备份多个表,执行 br backup full 命令,并使用 --filter 或 -f 来指定表库过滤规则。用例:以下命令将所有 db*.tbl* 形式的表格数据备份到每个 TiKV 节点上的 /tmp/backup 路径,并将 backupmeta 文件写入该路径。br backup full
--pd "${PDIP}:2379"
--filter db*.tbl*
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backupfull.log
3) 恢复数据
要将全部备份数据恢复到集群中来,可使用 br restore full 命令。该命令的使用帮助可以通过 br restore full -h 或 br restore full --help 来获取。用例:将 /tmp/backup 路径中的全部备份数据恢复到集群中。br restore full
--pd "${PDIP}:2379"
--storage "local:///tmp/backup"
--ratelimit 128
--log-file restorefull.log
以上命令中,--ratelimit 选项限制了每个 TiKV 执行恢复任务的速度上限(单位 MiB/s)。--log-file 选项指定把 BR 的 log 写到 restorefull.log 文件中。要将备份数据中的某个数据库恢复到集群中,可以使用 br restore db 命令。该命令的使用帮助可以通过 br restore db -h 或 br restore db --help 来获取。用例:将 /tmp/backup 路径中备份数据中的某个数据库恢复到集群中。br restore db
--pd "${PDIP}:2379"
--db "test"
--ratelimit 128
--storage "local:///tmp/backup"
--log-file restorefull.log
以上命令中 --db 选项指定了需要恢复的数据库名字。其余选项的含义与恢复全部备份数据相同。要将备份数据中的某张数据表恢复到集群中,可以使用 br restore table 命令。该命令的使用帮助可通过 br restore table -h 或 br restore table --help 来获取。用例:将 /tmp/backup 路径下的备份数据中的某个数据表恢复到集群中。br restore table
--pd "${PDIP}:2379"
--db "test"
--table "usertable"
--ratelimit 128
--storage "local:///tmp/backup"
--log-file restorefull.log
如果你需要用复杂的过滤条件来恢复多个表,执行 br restore full 命令,并用 --filter 或 -f 指定使用表库过滤。用例:以下命令将备份在 /tmp/backup 路径的表的子集恢复到集群中。br restore full
--pd "${PDIP}:2379"
--filter db*.tbl*
--storage "local:///tmp/backup"
--log-file restorefull.log
3.2 TiCDC异地库备份
B集群作为备份集群,GC time设置为 1天,生产A集群需要恢复数据时,可通过Dumpling工具导出指定时间点之前数据,进行数据恢复。3.3 DumplingTiDB Lightning备份恢复
输出文件格式:
- metadata:此文件包含导出的起始时间,以及 master binary log 的位置。
Started dump at: 2020-11-10 10:40:19
SHOW MASTER STATUS:
Log: tidb-binlog
Pos: 420747102018863124
Finished dump at: 2020-11-10 10:40:20
- {schema}-schema-create.sql:创建 schema 的 SQL 文件。
CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
- {schema}.{table}-schema.sql:创建 table 的 SQL 文件。
CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
- {schema}.{table}.{0001}.{sql|csv}:数据源文件。
/*!40101 SET NAMES binary*/;
INSERT INTO `t1` VALUES
(1);
1) 备份工具Dumpling
该工具可以把存储在 TiDB/MySQL 中的数据导出为 SQL 或者 CSV 格式,可以用于完成逻辑上的全量备份或者导出。./dumpling
-u root
-P 4000
-h 127.0.0.1
--filetype sql
-o /tmp/test
-t 8
-r 200000
-F 256MiB
- --filetype:导出文件类型,sql|csv。
- -t:用于指定导出的线程数。增加线程数会增加 Dumpling 并发度提高导出速度,但也会加大数据库内存消耗,因此不宜设置过大。
- -r:用于指定单个文件的最大行数,指定该参数后 Dumpling 会开启表内并发加速导出,同时减少内存使用。
- -F:选项用于指定单个文件的最大大小(单位为 MiB,可接受类似 5GiB 或 8KB 的输入)。
例: --filter "employees.*" 例: --sql select * from `test`.`sbtest1` where id < 100参数列表:
| | |
| | |
| | |
| | |
| 导出能匹配模式的表,语法可参考 filter.txt | |
| | |
| | |
| | |
| 将 table 划分成 row 行数据,一般针对大表操作并发生成多个文件。 | |
| | |
| 日志级别 {debug,info,warn,error,dpanic,panic,fatal} | |
| | |
| | |
| 导出 csv 格式的 table 数据,不生成 header | |
| | |
| | |
| 控制 INSERT SQL 语句的大小,单位 bytes | |
| 将 table 数据划分出来的文件大小,需指明单位(如 128B, 64KiB, 32MiB, 1.5GiB) | |
| | |
| | |
| 根据指定的 sql 导出数据,该选项不支持并发导出 | |
| | |
| snapshot: 通过 TSO 来指定 dump 某个快照时间点的 TiDB 数据 |
| lock: 对需要 dump 的所有表执行 lock tables read 命令 |
|
| auto: MySQL 默认用 flush, TiDB 默认用 snapshot |
| snapshot tso,只在 consistency=snapshot 下生效 | |
| | |
| | |
| | |
| | |
| | |
| 用于 TLS 连接的 certificate authority 文件的地址 | |
| 用于 TLS 连接的 client certificate 文件的地址 | |
| 用于 TLS 连接的 client private key 文件的地址 | |
| | |
| | |
| | |
| | |
| --output-filename-template | 以 golang template 格式表示的数据文件名格式 | {{.DB}}.{{.Table}}.{{.Index}} |
| 支持 {{.DB}}、{{.Table}}、{{.Index}} 三个参数 |
|
| Dumpling 的服务地址,包含了 Prometheus 拉取 metrics 信息及 pprof 调试的地址 | |
| 单条 dumpling 命令导出 SQL 语句的内存限制,单位为 byte,默认为 32 GB | |
2) 恢复工具Tidb Lightning
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具。tidb-lightning --config cfg.toml --backend tidb -tidb-
host 127.0.0.1 -tidb-user root --tidb-password passwd -
tidb-port 4000 -d /home/tidb/bakfile/9
Local-backend 工作原理: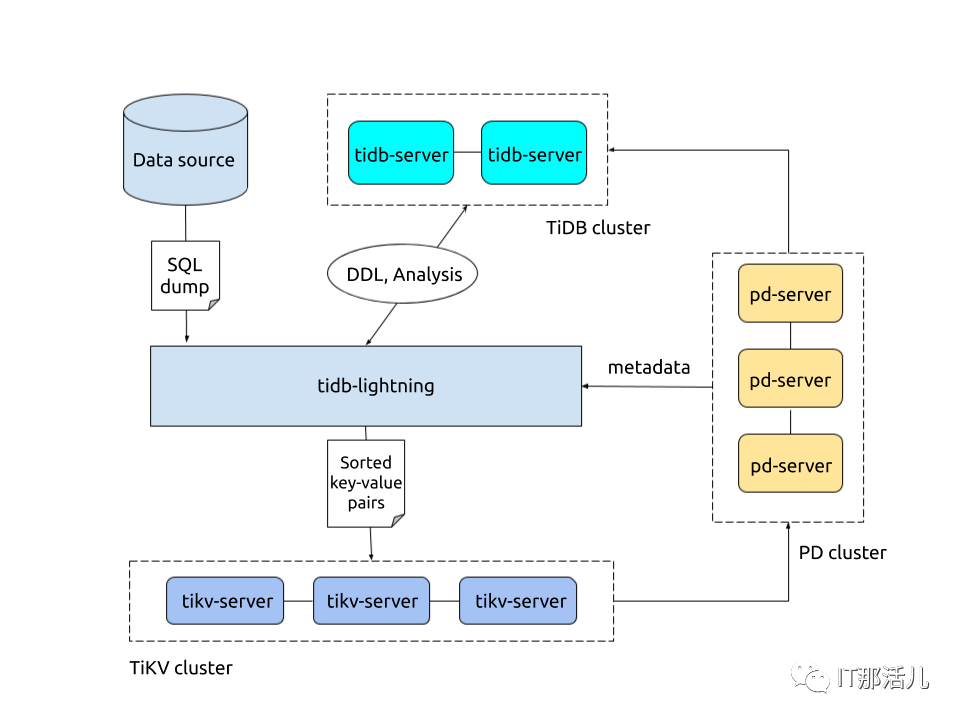
TiDB Lightning 整体工作原理如下:
- i) 在导入数据之前,tidb-lightning 会自动将 TiKV 集群切换为“导入模式” (import mode),优化写入效率并停止自动压缩。
- ii) tidb-lightning 会在目标数据库建立架构和表,并获取其元数据。
- iii) 每张表都会被分割为多个连续的区块,这样来自大表 (200 GB+) 的数据就可以用增量方式并行导入。
- iv) tidb-lightning 会为每一个区块准备一个“引擎文件 (engine file)”来处理键值对。tidb-lightning 会并发读取 SQL dump,将数据源转换成与 TiDB 相同编码的键值对,然后将这些键值对排序写入本地临时存储文件中。
- v) 当一个引擎文件数据写入完毕时,tidb-lightning 便开始对目标 TiKV 集群数据进行分裂和调度,然后导入数据到 TiKV 集群。
- vi) 引擎文件包含两种:数据引擎与索引引擎,各自又对应两种键值对:行数据和次级索引。通常行数据在数据源里是完全有序的,而次级索引是无序的。因此,数据引擎文件在对应区块写入完成后会被立即上传,而所有的索引引擎文件只有在整张表所有区块编码完成后才会执行导入。
- vii) 整张表相关联的所有引擎文件完成导入后,tidb-lightning 会对比本地数据源及下游集群的校验和 (checksum),确保导入的数据无损,然后让 TiDB 分析 (ANALYZE) 这些新增的数据,以优化日后的操作。同时,tidb-lightning 调整 AUTO_INCREMENT 值防止之后新增数据时发生冲突。
- viii) 表的自增 ID 是通过行数的上界估计值得到的,与表的数据文件总大小成正比。因此,最后的自增 ID 通常比实际行数大得多。这属于正常现象,因为在 TiDB 中自增 ID 不一定是连续分配的。
- viiii) 在所有步骤完毕后,tidb-lightning 自动将 TiKV 切换回“普通模式” (normal mode),此后 TiDB 集群可以正常对外提供服务。
参数列表:
| | |
| 从 file 读取全局设置。如果没有指定则使用默认设置。 | |
| | |
| | |
| 日志的等级:debug、info、warn、error 或 fatal (默认为 info) | |
| | |
| 选择后端的模式:importer、local 或 tidb | |
| | |
| | |
| | |
| | |
| | |
| TiDB Server 的端口(默认为 4000) | |
| TiDB Server 的状态端口的(默认为 10080) | |
| | |
| | |
| 忽略表结构文件,直接从 TiDB 中获取表结构信息 | |
| | |
| | |
| | |
| --check-requirements bool | | lightning.check-requirements |
| | |
| | |
| | |
| | |
backend各模式区别:
参考: https://asktug.com/t/topic/636754.1 误drop库
1) 确认删除时间
删库这种操作权限一般只有管理员才会有,当然也不排除有部分开发人员申请了超级权限,如果这个事情发生了那么我们肯定是希望能精确找到删库的时间点这样可以减少数据丢失,好在Tidb记录了所以DDL操作,可以通过adminshowddljobs;查看,找到删库的具体时间点。2) 确认数据的有效性
通过上面方法我们可以确认drop 库的操作是在 2020-11-17 08:26:36 ,那么我们需要这个时间点的前几秒的快照应该就有被我们删除的库,通过 set @@tidb_snapshot="xx-xx-xx xx:xx:xx"; 设置当前session查询该历史快照数据。3) 备份数据
dumpling -h 172.21.xx.xx -P 4000 -uroot -p xxx -t 32 -F 64MiB -B xxx_ods --snapshot "2020-11-17 08:26:35" -o ./da
4) 恢复数据
myloader -h 172.21.xx.xx -u root -P 4000 -t 32 -d ./da -p xxx
1) 确认操作时间
通过 admin show ddl jobs 确认truncate的操作的开始时间。2) 将数据写入到临时表
通过 set @@tidb_snapshot="xx-xx-xx xx:xx:xx"; 设置当前session查询该历史快照数据。FLASHBACK TABLE xxx_comment TO xxx_comment_bak_20201117;
如果线上的这张表没有新数据写入或者新数据可以不要,那么可以这样操作:drop table xxx_comment ;
rename table xxx_comment_bak_20201117 to xxx_comment;
如果线上的表还在继续有新数据写入并且不能破坏,那么可以把恢复出来的临时表的数据在写会到线上表。insert into xxx_comment select * from xxx_comment_bak_20201117;
1) 确认操作时间
通过 admin show ddl jobs 确认truncate的操作的开始时间。2) 恢复表
RECOVER TABLE xxx_comment ;
最近 DDL JOB 历史中找到的第一个 DROP TABLE 操作,且 DROP TABLE 所删除的表的名称与 RECOVER TABLE 语句指定表名相同 ,如果这个表执行过多次删除再建的操作,你想恢复到第一次的删除操作之前的数据,可以通过 RECOVER TABLE BY JOB 827; 恢复,其中827是通过 admin show ddl jobs ; 确认的job id。4.4 误 delete、update表
1) 确认操作时间
对于DML的误操作,如图Tidb集群没开启全日志,基本没办法从集群层面确认误操作时间了,需要从误操作发起端介入排查了。如果是管理员命令行误操作,可以通过堡垒机的操作记录去人;如果是程序bug可以通过排查程序的日志确认执行误操作的时间。2) 确认数据的有效性
通过上面方法我们可以确认误操作是在 2020-11-17 10:28:25 ,那么我们需要这个时间点的前几秒的快照应该就有被我们删除的库,通过set @@tidb_snapshot=“xx-xx-xx xx:xx:xx”; 设置当前session查询该历史快照数据。3) 备份数据
通过dumpling把上面确定的时间点的快照数据备份出来:dumpling -h 172.21.xx.xx -P 4000 -uroot -p xxx -t 32 -F
64MiB -B xxx_ods -T xxx_ods.xxx_comment --snapshot "2020-
11-17 09:55:00" -o ./da
4) 恢复数据
把上面备份的数据导入到一个临时实例里面,确认下数据没问题可以在临时实例里面把这个表重命名,然后导入到线上库,最后把数据合并到线上的表里面。myloader -h 172.21.xx.xx -u root -P 4001 -t 32 -d ./da -p xxx
5.1 中控有备份
中控有备份,那么我们可以直接通过中控的备份进行恢复;1) 中控备份
TiUP 相关的数据都存储在用户home目录的 .tiup 目录下,若要迁移中控机只需要拷贝 .tiup 目录到对应目标机器即可。中控备份:tar czvf tiup.tar.gz .tiup。为了避免中控机磁盘损坏或异常宕机等情况导致TiUP数据丢失,建议线上环境定时备份.tiup 目录,写一个简单的脚本就可以搞定。2) 恢复方法
- i) 把 tiup.tar.gz 拷贝到目标机器home目录。
- ii) 在目标机器 home 目录下执行 tar xzvf tiup.tar.gz。
- iii) 添加 .tiup 目录到 PATH 环境变量。
如使用 bash 并且是 tidb 用户,在 ~/.bashrc 中添加 export PATH=/home/tidb/.tiup/bin:$PATH 后执行 source ~/.bashrc,根据使用的 shell 与用户做相应调整。5.2 中控没有备份
针对中控没有备份,那么其实恢复方案也相对比较简单。恢复方法:
- ii) 根据运行的集群组件,重新配置一个集群的拓扑文件。
- iii) 执行deploy命令:tiup cluster deploy tidb-xxx ./topology.yaml。
- iv) 执行完成之后,不需要start集群,因为集群本身是在运行的,执行display查看一下集群的节点状态即可。
5.3 注意事项
6.1 集群状态
1) 实例
2) 主机
3) 磁盘
4) 存储拓扑
5) 监控告警
6.2 Sql语句
6.3 慢查询
6.4 流量可视化
6.5 集群诊断报告

文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/129138.html



