
python sklearn:教你如何画出决策书,并保存为PDF的实现过程
这篇文章主要介绍了python sklearn画出决策树并保存为PDF的实现过程,这篇文章具有很高的参考价值,希望各位读者可以认真仔细的阅读。
利用sklearn画出决策树并保存为PDF
下载Graphviz
进入官网下载并安装:
https://graphviz.gitlab.io/_pages/Download/Download_windows.html
并将下列路径配置为环境变量:
D:softwareGraphvizbin
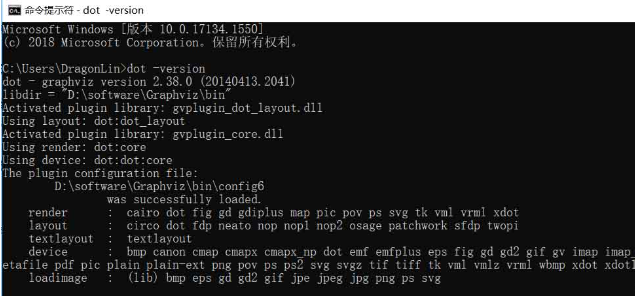
在cmd中测试:
dot -version
python代码
import numpy as np
import pandas as pd
from sklearn import tree
import graphviz
# x,y是sklearn中需要拟合的数据
x = np.array(exam_train)
y = np.array(classes_train)
clf = tree.DecisionTreeClassifier(criterion='entropy', class_weight='balanced', max_depth=25)
clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=None, filled=True, rounded=True) # 重要参数可定制
graph = graphviz.Source(dot_data)
graph.render(view=True, format="pdf", filename="decisiontree_pdf")可以生成一张贼帅的决策树PDF

python sklearn决策树运用
数据形式(tree.csv)
age look income orderly target
older ugly low yes no
young ugly high no no
young handsome low no no
young handsome high yes yes
young handsome medium yes yes
young handsome medium no no 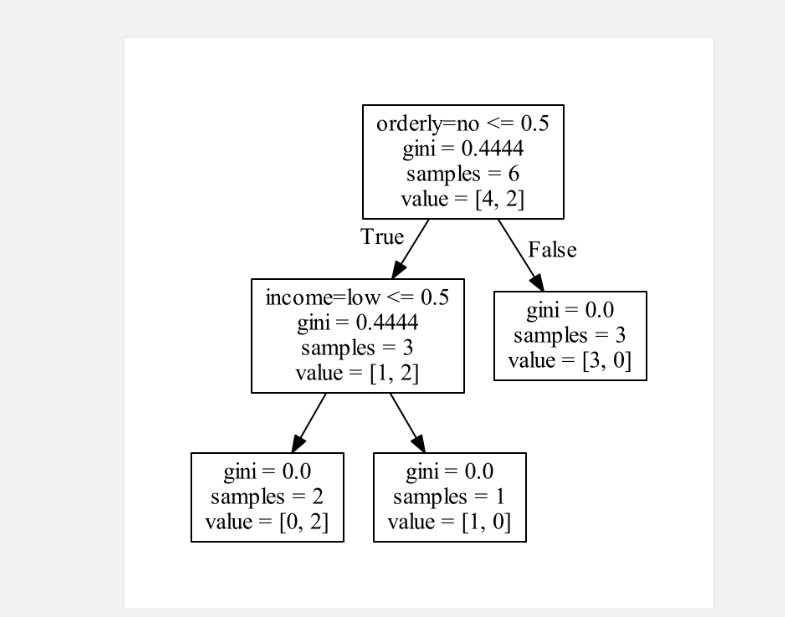
python源代码:
# -*- coding:utf-8*-
# 将字典 转化为 sklearn 用的数据形式 数据型 矩阵
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree
allElectronicsData = open('c:/pic/data/tree.csv','rb')
reader = csv.reader(allElectronicsData)
header = reader.next()
# print header
## 数据预处理
featureList = []
labelList = []
for row in reader:
# print row[-1]
labelList.append(row[-1])
# 下面这几步的目的是为了让特征值转化成一种字典的形式,就可以调用sk-learn里面的DictVectorizer,直接将特征的类别值转化成0,1值
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[header[i]] = row[i]
featureList.append(rowDict)
for each in featureList:
print each
# Vectorize features
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:"+str(dummyX))
print(vec.get_feature_names())
# label的转化,直接用preprocessing的LabelBinarizer方法
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:"+str(dummyY))
print("labelList:"+str(labelList))
#criterion是选择决策树节点的 标准 ,这里是按照“熵”为标准,即ID3算法;默认标准是gini index,即CART算法。
clf = tree.DecisionTreeClassifier()
clf = clf.fit(dummyX,dummyY)
print("clf:"+str(clf))
# 导入相关函数,可视化决策树
# 导出的结果是一个dot文件(在系统默认路劲),需要安装Graphviz才能将它住哪华为PDF或png格式
# 输出的dot文件可以使用graphvize软件转为PDF,graphvize安装目录中的bin目录放入到环境变量的Path中
# 使用如下命令
#cmd
# dot -Tpdf c:/tree.dot -o c:/tree.pdf
#下载地址:http://www.graphviz.org/Download_windows.php
#生成dot文件
with open("c:/tree.dot",'w') as f:
f = tree.export_graphviz(clf, feature_names= vec.get_feature_names(),out_file= f)以上就是小编给大家的详细解答了,希望可以为各位读者带来帮助
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/127554.html
摘要:起步在理论篇我们介绍了决策树的构建和一些关于熵的计算方法,这篇文章将根据一个例子,用代码上来实现决策树。转化文件至可视化决策树的命令得到一个文件,打开可以看到决策树附录本次应用的全部代码向量化向量化构造决策树保存模型测试数据 起步 在理论篇我们介绍了决策树的构建和一些关于熵的计算方法,这篇文章将根据一个例子,用代码上来实现决策树。 实验环境 操作系统: win10 64 编程语言: ...
马上就要开始啦这次共组织15个组队学习 涵盖了AI领域从理论知识到动手实践的内容 按照下面给出的最完备学习路线分类 难度系数分为低、中、高三档 可以按照需要参加 - 学习路线 - showImg(https://segmentfault.com/img/remote/1460000019082128); showImg(https://segmentfault.com/img/remote/...
摘要:决策树分支转存写代码的方法今天是周日,我还在倒腾决策树,然后发现了一个不用装软件也能倒的方法,而且更简单。刚开始看视频的时候是看的的视频,讲的真差,太模糊了,不适合我。 决策树分支dot转存pdf 1、写代码的方法 今天是周日,我还在倒腾决策树,然后发现了一个不用装软件也能倒pdf的方法,而且更简单。参照了这个中文的文档实现:http://sklearn.apachecn.org/c....
阅读 1045·2023-01-14 11:38
阅读 1042·2023-01-14 11:04
阅读 874·2023-01-14 10:48
阅读 2330·2023-01-14 10:34
阅读 1117·2023-01-14 10:24
阅读 1008·2023-01-14 10:18
阅读 636·2023-01-14 10:09
阅读 710·2023-01-14 10:02




