
在日常向领导汇报工作的时候,PPT使用次数是比较多的,那么,怎么才能提高工作效率,更快的去完成PPT呢?下面,小编就给大家总结了一些代码实例,希望大家以后在工作中能够遇到。
在日常工作中,PPT制作是常见的工作,那么慢,怎么快速的进行制作,确是十分考验人的能力的。
如果我们想要把PPT做的更好看一些,比如去制作创意类PPT,则无法通过自动化的形式生成,因为创意本身具有随机性,而自动化解决的是重复性工作,所以两者就会产生一定的冲突。
python-pptx是python处理PPT的一个库,注重的是读和写,无法导出,没有渲染功能,那么,到底该如何使用呢,下面给读者一步一步的进行拆解。
第一步,安装python-pptx库:
pip3 install-i https://pypi.doubanio.com/simple/python-pptxppt里面处理的主要对象一般为文本框,表格,图片。
每一页的ppt为一个slide
from pptx import Presentation,util
from pptx.util import Pt,Cm
from pptx.shapes.picture import Picture
#实例化一个ppt对象
ppt=Presentation("./test.pptx")
slide=ppt.slides[0]#第几页然后遍历查看这一页ppt中都包含哪些对象:
def rander_template(slide):
for shape in slide.shapes:
if shape.has_text_frame==True:
print("==========================文本框=============================")
print("段落长度:",len(shape.text_frame.paragraphs))
for paragraph in shape.text_frame.paragraphs:
#拼接文字
print("段落包含字段:",len(paragraph.runs))
print(''.join(run.text for run in paragraph.runs))
for i in range(len(paragraph.runs)):
print("run"+str(i)+":"+paragraph.runs<i>.text)
print(shape.text_frame.paragraphs[0].runs[0].text)
shape.text_frame.paragraphs[0].runs[0].text="规则是自由的第一要义"
elif shape.has_table==True:
print("==========================表格==============================")
one_table_data=[]
for row in shape.table.rows:#读每行
row_data=[]
for cell in row.cells:#读一行中的所有单元格
cell.text=cell.text if cell.text!=""else"未填写"
c=cell.text
row_data.append(c)
one_table_data.append(row_data)#把每一行存入表
#用二维列表输出表格行和列的数据
print(one_table_data)
print("第一个单元格内容:",shape.table.rows[0].cells[0].text)
elif isinstance(shape,Picture):
print("==========================图片==============================")
index=0
with open(f'{index}.jpg','wb')as f:
f.write(shape.image.blob)
index+=1文本框对象【text_frame】:
shape.has_text_frame查看是否有文本框对象,有的话查看具体有几个段落【len(shape.text_frame.paragraphs)】,每个段落又 有多少个run对象【len(paragraph.runs)】
注意:修改run对象的时候,修改run[0],后面的值都会被覆盖。
表格对象【table】:
table对象还是按照行列值来定位划分的,eg:table.rows[2]cells[3].text代表第三行第四列的值
图片对象【Picture】:
插入图片需要固定图片的位置,比如:

全部代码:
def insert_pic(slide):
#需要用到pptx库的util方法
img_path = './blue.png' # 图片路径
# 设置图片的位置和大小
left = util.Cm(8.04)
top = util.Cm(9.93)
width = util.Cm(15.07)
height = util.Cm(4.06)
# 在页面中插入图片
slide.shapes.add_picture(img_path, left, top, width, height)
from pptx import Presentation, util
from pptx.util import Pt,Cm
from pptx.shapes.picture import Picture
ppt = Presentation("./test.pptx")
def rander_template(slide):
for shape in slide.shapes:
if shape.has_text_frame == True:
print("==========================文本框=============================")
print("段落长度:",len(shape.text_frame.paragraphs))
for paragraph in shape.text_frame.paragraphs:
# 拼接文字
print("段落包含字段:",len(paragraph.runs))
print(''.join(run.text for run in paragraph.runs))
for i in range(len(paragraph.runs)):
print("run"+str(i)+":"+paragraph.runs[i].text)
print(shape.text_frame.paragraphs[0].runs[0].text)
shape.text_frame.paragraphs[0].runs[0].text = "规则是自由的第一要义"
elif shape.has_table == True:
print("==========================表格==============================")
one_table_data = []
for row in shape.table.rows: # 读每行
row_data = []
for cell in row.cells: # 读一行中的所有单元格
cell.text = cell.text if cell.text != "" else "未填写"
c = cell.text
row_data.append(c)
one_table_data.append(row_data) # 把每一行存入表
# 用二维列表输出表格行和列的数据
print(one_table_data)
print("第一个单元格内容:",shape.table.rows[0].cells[0].text)
elif isinstance(shape,Picture):
print("==========================图片==============================")
index = 0
with open(f'{index}.jpg','wb') as f:
f.write(shape.image.blob)
index += 1
def insert_pic(slide):
img_path = './blue.png' # 图片路径
# 设置图片的位置和大小
left = util.Cm(8.04)
top = util.Cm(9.93)
width = util.Cm(15.07)
height = util.Cm(4.06)
# 在页面中插入图片
slide.shapes.add_picture(img_path, left, top, width, height)
if __name__ == "__main__":
slide = ppt.slides[0] #第几页
rander_template(slide)
insert_pic(slide)
ppt.save('new.pptx') # 保存为文件初始ppt:
生成ppt:
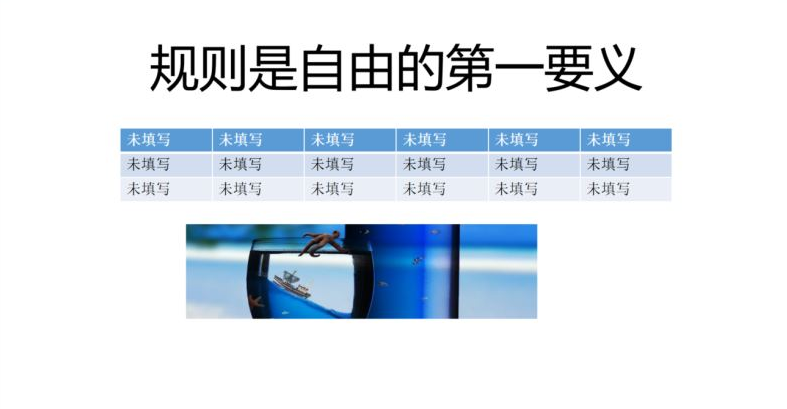
关于Python自动生产PPT的文章就为大家介绍到这里了,希望能给大家带来帮助。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/127545.html
摘要:基于云迁移的三个阶段细分为八个主要步骤,评估阶段主要包括项目启动现状梳理以及应用系统关联关系分析三个步骤,设计阶段包括云架构优化设计和云迁移方案设计,实施阶段包括目标架构迁移演练及实施和试运行三个步骤。 在云计算市场规模不断扩大的大背景下,云迁移的需求越来越大且面临挑战。云迁移不是一个迁移软件工具,而是一种服务。前IBM资深架构师姜亚杰从云迁移的三个阶段、四个维度到八个步骤的方法,简述...
摘要:上班太忙没时间自己学习很多人认为自己没有成为技术大牛并不是自己不聪明,也不是自己不努力,而是中国的这个环境下,技术人员加班都太多了,导致自己没有额外的时间进行学习。 写在前面 不管是开发、测试、运维,每个技术人员心里多多少少都有一个成为技术大牛的梦,毕竟梦想总是要有的,万一实现了呢!正是对技术梦的追求,促使我们不断地努力和提升自己。然而梦想是美好的,现实却是残酷的,很多同学在实际工作后...
摘要:我们以请求网络服务为例,来实际测试一下加入多线程之后的效果。所以,执行密集型操作时,多线程是有用的,对于密集型操作,则每次只能使用一个线程。说到这里,对于密集型,可以使用多线程或者多进程来提高效率。 为了提高系统密集型运算的效率,我们常常会使用到多个进程或者是多个线程,python中的Threading包实现了线程,multiprocessing 包则实现了多进程。而在3.2版本的py...
摘要:作为面试官,我是如何甄别应聘者的包装程度语言和等其他语言的对比分析和主从复制的原理详解和持久化的原理是什么面试中经常被问到的持久化与恢复实现故障恢复自动化详解哨兵技术查漏补缺最易错过的技术要点大扫盲意外宕机不难解决,但你真的懂数据恢复吗每秒 作为面试官,我是如何甄别应聘者的包装程度Go语言和Java、python等其他语言的对比分析 Redis和MySQL Redis:主从复制的原理详...
阅读 1372·2023-01-14 11:38
阅读 1439·2023-01-14 11:04
阅读 1192·2023-01-14 10:48
阅读 3010·2023-01-14 10:34
阅读 1554·2023-01-14 10:24
阅读 1477·2023-01-14 10:18
阅读 937·2023-01-14 10:09
阅读 1119·2023-01-14 10:02






