
摘要:也可以将托管集群设置为快捷方式,通过左侧快捷方式菜单栏点击进入。框架集群中仅部署。用于做存储集群,有专属的节点机型。节点管理节点,负责协调整个集群服务。目前仅节点支持绑定。通过云主机内网进行登录。登录密码为集群创建时设置的密码。
本文档将带领您如何创建UHadoop集群,并使用UHadoop集群完成数据处理任务。
本章简单介绍了用户使用UHadoop服务时如何快速创建集群,如已创建完毕,请跳至第二章查看如何提交任务。
1、进入产品页面在“全部产品”菜单中点击“托管Hadoop集群 UHadoop”进入产品页面。
也可以将“托管Hadoop集群 UHadoop”设置为快捷方式,通过左侧快捷方式菜单栏点击进入。
2、点击【创建集群】按钮3、按需配置【基本设置】4、软件设置VPC和子网信息必填。详情参考私有网络VPC。
该模块提供集群软件、集群框架的选择。
集群框架:
根据应用场景的不同,可选择不同的集群框架。
Hadoop框架 集群中同时部署HDFS和YARN,适用于存储和计算在同一集群。
HDFS框架 集群中仅部署HDFS。用于做存储集群,有专属的HDFS节点机型。
计算框架 不部署HDFS,仅部署YARN。
HDFS框架和计算框架适用于存储计算分离架构。HDFS集群可作为多个独立计算集群的存储集群。 计算集群和存储集群(Hadoop框架、HDFS框架)的关系是多对一。可以在集群详情页看到已经联通的集群。
创建计算集群前需要您已有HDFS集群或Hadoop框架的集群。选择计算集群后,必须要指定【集群存储】,即指定计算集群读写数据的位置。
发行版:
发行版命名方式:uhadoop [ 版本号 ]
每个发行版中有多个大数据生态软件,如HBase、Spark、Hive等。
框架版本:
集群中 Hadoop 的版本,不同发行版的框架版本不同。
集群种类:
不同种类代表集群会安装不同的集群软件。未在此处选择的软件,也可在集群创建完成后,通过集群管理添加。
5、节点设置节点配额总量 最多可创建的节点数量。如需更大配额,可联系客户经理或技术支持申请开通。
Master节点 管理节点,负责协调整个集群服务。一个集群中有且仅有两个管理节点,一主一备,保证高可用。 除了基础服务(如Hadoop、Hive、HBase)的管理端部署在Master上外,一些插件(如Hue、Oozie、Sqoop2、Airflow)也会安装于Master节点上,因此,如若安装大量插件服务,Master节点配置建议高于C1-2xlarge。
Core节点 核心节点,用于存储数据(HDFS)与运行任务。由于核心节点用于存储数据,因此数量须大于等于2(默认集群文件副本数配置为3),您可以根据业务需求添加更多的核心节点。
Task节点 任务节点,用于执行任务。任务节点不存储数据,您可以在集群运行期间动态进行添加和删除。
不同磁盘类型配置选择建议 第一参考是数据量,数据量按照您需求的业务数据量*3计算(HDFS默认将文件存储3份拷贝,来保证高可用)。 若数据量超过6T后,推荐使用密集存储系列节点(密集存储系列采用SATA硬盘,更适合海量数据的存储)。 若对磁盘性能和存储量都有需求,可使用物理机。
不同CPU、MEM机型的选择 CPU、MEM的选择可按照计算复杂度与数据读写的频度,如果计算不是很复杂,小配置即可,如果复杂度较高,建议4核以上机型。 Spark对内存需求较大,建议选择12G MEM以上的机型。
6、访问设置了解各节点配置详情,请参考产品价格。
填充节点root密码。
7、等待集群部署根据集群规模不同,所需要的部署时间会有所差异,创建时间基本在15分钟左右。
在集群创建成功后,点击集群管理,进入集群节点详情页面。
2、登录集群
通过控制台登录。
绑定外网eip,本地可通过外网ssh连接登录。目前仅master节点支持绑定。
Eip使用详情请见EIP说明文档。
本例中可通过`ssh root@106.75.135.10 -p22`进行登录。
通过云主机(uhost)内网ssh进行登录。
本例中可在云主机上通过`ssh root@10.13.186.23 -p22`进行登录。
3、任务提交登录密码为集群创建时设置的密码。
利用hadoop命令查看hdfs目录信息
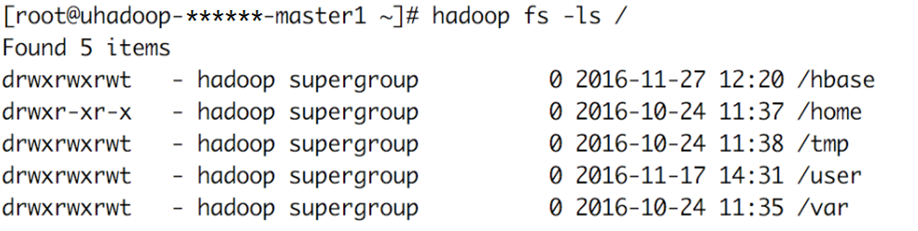
创建目录,并上传测试数据
[root@uhadoop-******-master1 ~]# hadoop fs -mkdir /input
[root@uhadoop-******-master1 ~]# hadoop fs -put /home/hadoop/conf/* /input执行WordCount任务
[root@uhadoop-******-master1 ~]# hadoop jar /home/hadoop/hadoop-examples.jar wordcount /input /output如果/output目录已存在,请删除该目录或使用其他目录。
查看wordcount任务的结果
[root@uhadoop-******-master1 ~]# hadoop fs -cat /output/part-r-00000
!= 3
"" 6
"". 4
"$HADOOP_CLASSPATH" 1
"$JAVA_HOME" 2
"$YARN_HEAPSIZE" 1
"$YARN_LOGFILE" 1
"$YARN_LOG_DIR" 1
"$YARN_POLICYFILE" 1
"*" 17
...若集群安装了spark服务,可提交spark任务
spark-submit --master yarn --deploy-mode client --num-executors 1 --executor-cores 1 --executor-memory 1G $SPARK_HOME/examples/src/main/python/pi.py 100屏幕信息中会打印任务执行结果:
Pi is roughly 3.141313更多使用内容,请参考 UHadoop开发指南
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/127035.html

摘要:集群运行慢时,通常会在日志中可以查找到明显的异常,或者花费时间长的操作。检查集群节点的运行状态检查集群节点的运行状态管理群集上部署的各种服务。如果主节点遇到性能问题,整个群集都会受到影响。工作的不均衡分配可能会导致处理速度较慢。 故障排查本篇目录任务执行失败排查工具故障描述集群运行速度慢任务执行失败1.查看console输出日志查看任务执行时控制台输出的log,检查是否有ERROR2.查看任...
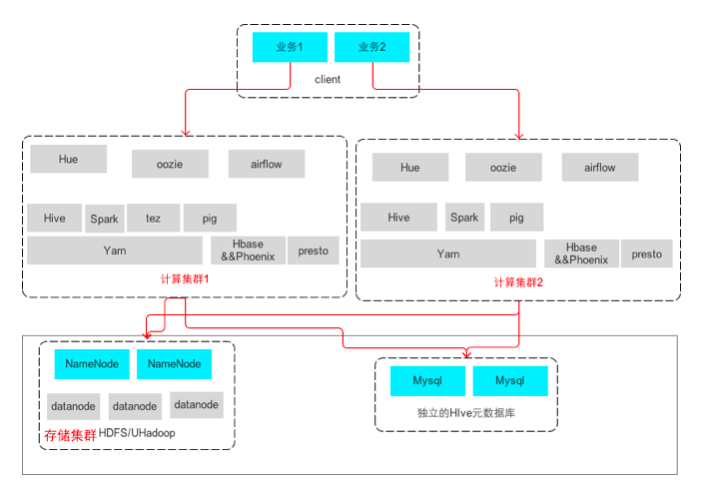
摘要:架构架构元数据管理元数据管理元数据管理创建集群时可在控制台开启元数据独立管理。若项目中已开启过元数据独立管理,则新集群开启该功能时,不再创建新的,而是将新集群的元数据存储于已有的中。 元数据管理本篇目录介绍产品架构元数据管理介绍UHadoop 支持将 Hive-Metastore 的数据库独立于 Hadoop 集群部署,也支持多个集群访问同一个 Hive 元数据库,可在控制台对其做管理。产品...
摘要:查看上的历史日志查看上的历史日志任务的日志在任务运行结束之后会上传到上,当日志文件过大无法通过来查看时,可以通过将日志文件从上下载下来查看。挂载在允许的主机上执行 常用操作本篇目录应用的Web接口查看日志配置NFS挂载hdfs到本地应用的Web接口Hadoop 提供了基于 Web 的用户界面,可通过它查看您的 Hadoop 集群。Web 服务会在主节点上运行(Active NameNode或...
摘要:产品价格产品价格产品价格托管集群价格根据节点类型及配置不同,北京上海广州香港可用区详细价格如下,其他可用区价格请咨询技术支持。 产品价格托管 Hadoop 集群价格根据节点类型及配置不同 ,北京、上海、广州、香港可用区详细价格如下,其他可用区价格请咨询技术支持。 节点类型机型名称CPU内存(G)硬盘(G)华北一E价格(元/月)国内其他可用区价格(元/月)Master&Task计算优化实例...
摘要:创建任务创建任务选择这个标签拖动到中。页面权限控制页面权限控制页面权限控制点击管理用户组选择要修改的组名称,设置相应权限并保存 Hue开发指南本篇目录1. 配置工作流2. Hue页面权限控制Hue是面向 Hadoop 的开源用户界面,可以让您更轻松地运行和开发 Hive 查询、管理 HDFS 中的文件、运行和开发 Pig 脚本以及管理表。服务默认已经启动,用户只需要配置外网IP,在防火墙中配...

阅读 1001·2025-02-07 13:29
阅读 812·2024-11-07 18:25
阅读 131254·2024-02-01 10:43
阅读 1130·2024-01-31 14:58
阅读 1076·2024-01-31 14:54
阅读 83385·2024-01-29 17:11
阅读 3638·2024-01-25 14:55
阅读 2300·2023-06-02 13:36
