
摘要:创建物化视图创建物化视图创建物化视图本篇目录官方文档官方文档基本语法查询语法参数说明参数描述物化视图的名称,必填项。物化视图的原始表名,必填项。由于物化视图没有声明排序列,且物化视图带聚合数据,系统默认补充分组列为排序列。
基本语法:
CREATE MATERIALIZED VIEW [MV name] as [query]
[PROPERTIES ("key" = "value")]查询语法:
SELECT select_expr[, select_expr ...]
FROM [Base view name]
GROUP BY column_name[, column_name ...]
ORDER BY column_name[, column_name ...]参数说明:
参数描述MVname物化视图的名称,必填项。相同表的物化视图名称不可重复。query用于构建物化视图的查询语句,查询语句的结果既物化视图的数据select_expr物化视图的schema中所有的列。仅支持不带表达式计算的单列,聚合列。其中聚合函数目前仅支持SUM,MIN,MAX三种,且聚合函数的参数只能是不带表达式计算的单列。至少包含一个单列。所有涉及到的列,均只能出现一次。baseviewname物化视图的原始表名,必填项。必须是单表,且非子查询groupby物化视图的分组列,选填项。不填则数据不进行分组orderby物化视图的排序列,选填项。排序列的声明顺序必须和select_expr中列声明顺序一致。如果不声明orderby,则根据规则自动补充排序列。如果物化视图是聚合类型,则所有的分组列自动补充为排序列。如果物化视图是非聚合类型,则前36个字节自动补充为排序列。如果自动补充的排序个数小于3个,则前三个作为排序列。如果query中包含分组列的话,则排序列必须和分组列一致。properties声明物化视图的一些配置,选填项properties如果Kafkaserver端开启了client认证,需要指定privatekey的密码short_key排序列的个数。timeout物化视图构建的超时时间。Base 表结构为
mysql> desc duplicate_table;
+-------+--------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+------+---------+-------+
| k1 | INT | Yes | true | N/A | |
| k2 | INT | Yes | true | N/A | |
| k3 | BIGINT | Yes | true | N/A | |
| k4 | BIGINT | Yes | true | N/A | |
+-------+--------+------+------+---------+-------+创建一个仅包含原始表 (k1, k2)列的物化视图
create materialized view k1_k2 as
select k1, k2 from duplicate_table;物化视图的 schema 如下图,物化视图仅包含两列 k1, k2 且不带任何聚合
+-----------------+-------+--------+------+------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-----------------+-------+--------+------+------+---------+-------+
| k1_k2 | k1 | INT | Yes | true | N/A | |
| | k2 | INT | Yes | true | N/A | |
+-----------------+-------+--------+------+------+---------+-------+创建一个以 k2 为排序列的物化视图
create materialized view k2_order as
select k2, k1 from duplicate_table order by k2;物化视图的 schema 如下图,物化视图仅包含两列 k2, k1,其中 k2 列为排序列,不带任何聚合。
+-----------------+-------+--------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-----------------+-------+--------+------+-------+---------+-------+
| k2_order | k2 | INT | Yes | true | N/A | |
| | k1 | INT | Yes | false | N/A | NONE |
+-----------------+-------+--------+------+-------+---------+-------+创建一个以 k1, k2 分组,k3 列为 SUM 聚合的物化视图
create materialized view k1_k2_sumk3 as
select k1, k2, sum(k3) from duplicate_table group by k1, k2;物化视图的 schema 如下图,物化视图包含两列 k1, k2,sum(k3) 其中 k1, k2 为分组列,sum(k3) 为根据 k1, k2 分组后的 k3 列的求和值。
由于物化视图没有声明排序列,且物化视图带聚合数据,系统默认补充分组列 k1, k2 为排序列。
+-----------------+-------+--------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-----------------+-------+--------+------+-------+---------+-------+
| k1_k2_sumk3 | k1 | INT | Yes | true | N/A | |
| | k2 | INT | Yes | true | N/A | |
| | k3 | BIGINT | Yes | false | N/A | SUM |
+-----------------+-------+--------+------+-------+---------+-------+创建一个去除重复行的物化视图
create materialized view deduplicate as
select k1, k2, k3, k4 from duplicate_table group by k1, k2, k3, k4;物化视图 schema 如下图,物化视图包含 k1, k2, k3, k4列,且不存在重复行。
+-----------------+-------+--------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-----------------+-------+--------+------+-------+---------+-------+
| deduplicate | k1 | INT | Yes | true | N/A | |
| | k2 | INT | Yes | true | N/A | |
| | k3 | BIGINT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
+-----------------+-------+--------+------+-------+---------+-------+创建一个不声明排序列的非聚合型物化视图 all_type_table 的 schema 如下
+-------+--------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-------+---------+-------+
| k1 | TINYINT | Yes | true | N/A | |
| k2 | SMALLINT | Yes | true | N/A | |
| k3 | INT | Yes | true | N/A | |
| k4 | BIGINT | Yes | true | N/A | |
| k5 | DECIMAL(9,0) | Yes | true | N/A | |
| k6 | DOUBLE | Yes | false | N/A | NONE |
| k7 | VARCHAR(20) | Yes | false | N/A | NONE |
+-------+--------------+------+-------+---------+-------+物化视图包含 k3, k4, k5, k6, k7 列,且不声明排序列,则创建语句如下:
create materialized view mv_1 as
select k3, k4, k5, k6, k7 from all_type_table;系统默认补充的排序列为 k3, k4, k5 三列。这三列类型的字节数之和为 4(INT) + 8(BIGINT) + 16(DECIMAL) = 28 < 36。所以补充的是这三列作为排序列。 物化视图的 schema 如下,可以看到其中 k3, k4, k5 列的 key 字段为 true,也就是排序列。k6, k7 列的 key 字段为 false,也就是非排序列。
+----------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+----------------+-------+--------------+------+-------+---------+-------+
| mv_1 | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,0) | Yes | true | N/A | |
| | k6 | DOUBLE | Yes | false | N/A | NONE |
| | k7 | VARCHAR(20) | Yes | false | N/A | NONE |
+----------------+-------+--------------+------+-------+---------+-------+创建物化视图的更多信息,请参见Create Materialized View。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/126827.html

摘要:概览概览概览产品动态产品介绍什么是云数据仓库产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级节点扩容重启实例重置管理员密码删除集群连接集群数据导入本地数据导入数据导入通过导入开发指南数据类型语法创建库创建表创建视图插入数 概览概览产品动态产品介绍什么是云数据仓库UDoris产品优势应用场景基本概念使用限制快速上手操作指南管理集群Backend配置升降级Frontend节点扩...
摘要:数据排序使用的列数,取最前面几列,不能超过总的列数。示例创建一个动态分区表。创建外部表创建外部表在创建外部表的目的是可以通过访问外部数据库。创建表时,关于和的数量和数据量的建议。 建表(Create Table)创建表语法:CREATE TABLE [IF NOT EXISTS] [database.]table ( column_definition_list, [inde...
摘要:概览概览概览产品动态产品介绍什么是云数据仓库产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级重启实例重置管理员密码删除集群连接集群数据同步本地数据导入数据导入数据导入间数据导入开发指南数据类型语法创建库创建表创建视图插入 概览概览产品动态产品介绍什么是云数据仓库 UClickHouse产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级重启实例重置管理员密码删...
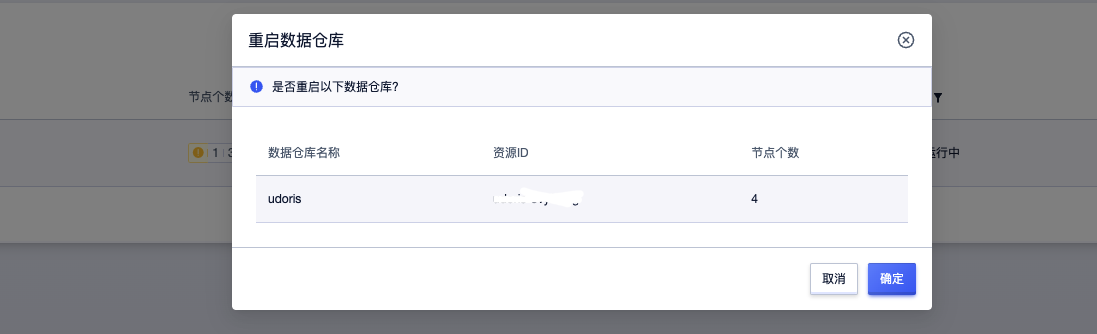
摘要:重启集群重启集群重启集群当您需要重启集群时,登录账号进入到用户控制台,在全部产品下搜索或者数据仓库下选择数据仓库,进入到数据仓库控制台下,选择操作重启注意重启集群为高危操作,集群将处于重启中持续数秒,建议无必要时不要随意重启实例,这将会 重启集群当您需要重启集群时,登录UCloud账号进入到用户控制台,在全部产品下搜索或者数据仓库下选择数据仓库 UDW Doris,进入到数据仓库UDoris...
摘要:如何连接云数据仓库如何连接云数据仓库如何连接云数据仓库为保证安全,云数据仓库仅提供内网网络,您连接集群时可以配合同一地域的云主机或者网络产品使用。 产品购买与使用本篇目录为什么只提供一种云盘类型?配置升降级对集群有什么影响?配置升级有什么建议?如何连接云数据仓库UDoris?为什么只提供一种云盘类型?Doris的存储特性对磁盘吞吐量要求很高,为保证Doris的性能优势, 因此仅提供RSSD云...

阅读 1366·2025-02-07 13:29
阅读 983·2024-11-07 18:25
阅读 131451·2024-02-01 10:43
阅读 1205·2024-01-31 14:58
阅读 1126·2024-01-31 14:54
阅读 83531·2024-01-29 17:11
阅读 3812·2024-01-25 14:55
阅读 2371·2023-06-02 13:36

