
摘要:修改表结构修改表结构修改表结构使用语句来完成表结构修改。注意无论是修改列还是列都需要声明完整的信息修改的列最大长度。原为重新排序中的列设原列顺序为同时执行两种操作更多信息,请具体参考官方文档
使用 ALTER TABLE COLUMN 语句来完成表结构修改。
该语句用于对已有 table 进行 Schema change 操作。schema change 是异步的,任务提交成功则返回,之后可使用SHOW ALTER 命令查看进度
基本语法:
ALTER TABLE [database.]table alter_clause;向指定 index 的指定位置添加一列
语法:
ADD COLUMN column_name column_type [KEY | agg_type] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]注意:
聚合模型如果增加 value 列,需要指定 agg_type非聚合模型(如 DUPLICATE KEY)如果增加key列,需要指定KEY关键字不能在 rollup index 中增加 base index 中已经存在的列(如有需要,可以重新创建一个 rollup index)向指定 index 添加多列
语法:
ADD COLUMN (column_name1 column_type [KEY | agg_type] DEFAULT "default_value", ...)
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]注意:
聚合模型如果增加 value 列,需要指定agg_type聚合模型如果增加key列,需要指定KEY关键字不能在 rollup index 中增加 base index 中已经存在的列(如有需要,可以重新创建一个 rollup index)从指定 index 中删除一列
语法:
DROP COLUMN column_name
[FROM rollup_index_name]注意:
不能删除分区列如果是从 base index 中删除列,则如果 rollup index 中包含该列,也会被删除修改指定 index 的列类型以及列位置
语法:
MODIFY COLUMN column_name column_type [KEY | agg_type] [NULL | NOT NULL] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]注意:
聚合模型如果修改 value 列,需要指定 agg_type非聚合类型如果修改key列,需要指定KEY关键字只能修改列的类型,列的其他属性维持原样(即其他属性需在语句中按照原属性显式的写出,参见 example 8)分区列和分桶列不能做任何修改目前支持以下类型的转换(精度损失由用户保证)TINYINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE 类型向范围更大的数字类型转换TINTINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE/DECIMAL 转换成 VARCHARVARCHAR 支持修改最大长度VARCHAR/CHAR 转换成 TINTINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLEVARCHAR/CHAR 转换成 DATE (目前支持"%Y-%m-%d", "%y-%m-%d", "%Y%m%d", "%y%m%d", "%Y/%m/%d, "%y/%m/%d"六种格式化格式)DATETIME 转换成 DATE(仅保留年-月-日信息, 例如:2019-12-09 21:47:05 <--> 2019-12-09)DATE 转换成 DATETIME(时分秒自动补零, 例如: 2019-12-09 <--> 2019-12-09 00:00:00)FLOAT 转换成 DOUBLEINT 转换成 DATE (如果INT类型数据不合法则转换失败,原始数据不变)对指定 index 的列进行重新排序
语法:
ORDER BY (column_name1, column_name2, ...)
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]注意:
index 中的所有列都要写出来value 列在 key 列之后示例向 example_rollup_index 的 col1 后添加一个key列 new_col(非聚合模型)ALTER TABLE example_db.my_table
ADD COLUMN new_col INT KEY DEFAULT "0" AFTER col1
TO example_rollup_index;ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;ALTER TABLE example_db.my_table
ADD COLUMN new_col INT SUM DEFAULT "0" AFTER col1
TO example_rollup_index;ALTER TABLE example_db.my_table
ADD COLUMN (col1 INT DEFAULT "1", col2 FLOAT SUM DEFAULT "2.3")
TO example_rollup_index;ALTER TABLE example_db.my_table
DROP COLUMN col2
FROM example_rollup_index;ALTER TABLE example_db.my_table
MODIFY COLUMN col1 BIGINT KEY DEFAULT "1" AFTER col2;注意:无论是修改 key 列还是 value 列都需要声明完整的 column 信息
修改 base index 的 val1 列最大长度。原 val1 为 (val1 VARCHAR(32) REPLACE DEFAULT "abc")ALTER TABLE example_db.my_table
MODIFY COLUMN val1 VARCHAR(64) REPLACE DEFAULT "abc";ALTER TABLE example_db.my_table
ORDER BY (k3,k1,k2,v2,v1)
FROM example_rollup_index;ALTER TABLE example_db.my_table
ADD COLUMN v2 INT MAX DEFAULT "0" AFTER k2 TO example_rollup_index,
ORDER BY (k3,k1,k2,v2,v1) FROM example_rollup_index;更多信息,请具体参考官方文档
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/126801.html

摘要:概览概览概览产品动态产品介绍什么是云数据仓库产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级节点扩容重启实例重置管理员密码删除集群连接集群数据导入本地数据导入数据导入通过导入开发指南数据类型语法创建库创建表创建视图插入数 概览概览产品动态产品介绍什么是云数据仓库UDoris产品优势应用场景基本概念使用限制快速上手操作指南管理集群Backend配置升降级Frontend节点扩...
摘要:数据排序使用的列数,取最前面几列,不能超过总的列数。示例创建一个动态分区表。创建外部表创建外部表在创建外部表的目的是可以通过访问外部数据库。创建表时,关于和的数量和数据量的建议。 建表(Create Table)创建表语法:CREATE TABLE [IF NOT EXISTS] [database.]table ( column_definition_list, [inde...
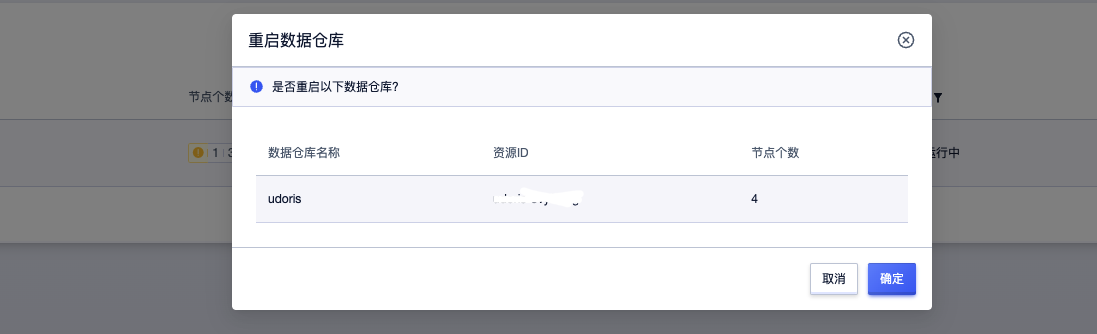
摘要:重启集群重启集群重启集群当您需要重启集群时,登录账号进入到用户控制台,在全部产品下搜索或者数据仓库下选择数据仓库,进入到数据仓库控制台下,选择操作重启注意重启集群为高危操作,集群将处于重启中持续数秒,建议无必要时不要随意重启实例,这将会 重启集群当您需要重启集群时,登录UCloud账号进入到用户控制台,在全部产品下搜索或者数据仓库下选择数据仓库 UDW Doris,进入到数据仓库UDoris...
摘要:如何连接云数据仓库如何连接云数据仓库如何连接云数据仓库为保证安全,云数据仓库仅提供内网网络,您连接集群时可以配合同一地域的云主机或者网络产品使用。 产品购买与使用本篇目录为什么只提供一种云盘类型?配置升降级对集群有什么影响?配置升级有什么建议?如何连接云数据仓库UDoris?为什么只提供一种云盘类型?Doris的存储特性对磁盘吞吐量要求很高,为保证Doris的性能优势, 因此仅提供RSSD云...
摘要:聚合函数函数名称描述语法统计行数或者非值个数求最小值求最大值统计行数或者非值个数去重计算输入的并集,返回新的计算输入的并集,返回其基数计算和类型的列中不同值的个数,返回值和相同非精确快速去重列的类型不能是或者且表为模型聚合函数函数名称描述语法 sum统计行数或者非NULL值个数sum(expr)min求最小值min(column)max求最大值max(column)count统计行数或...
摘要:概览概览概览产品动态产品介绍什么是云数据仓库产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级重启实例重置管理员密码删除集群连接集群数据同步本地数据导入数据导入数据导入间数据导入开发指南数据类型语法创建库创建表创建视图插入 概览概览产品动态产品介绍什么是云数据仓库 UClickHouse产品优势应用场景基本概念使用限制快速上手操作指南管理集群配置升降级重启实例重置管理员密码删...

阅读 2187·2025-02-07 13:29
阅读 1542·2024-11-07 18:25
阅读 132319·2024-02-01 10:43
阅读 2170·2024-01-31 14:58
阅读 1269·2024-01-31 14:54
阅读 84048·2024-01-29 17:11
阅读 4179·2024-01-25 14:55
阅读 2539·2023-06-02 13:36

