
摘要:如果长时间之后,集群的数据量还是不均衡,可以在集群管理页面提交数据均衡请求,如下图数据均衡数据均衡也可以在节点提交均衡命令是判断集群是否平衡的目标参数。
由于在UHadoop中Master配置是HA的,故NameNode也有2个,同一时刻一个节点为Active,另一个为Standby,一般内存跑高或者网络波动都可能会导致主从切换,不建议客户端使用Master节点IP访问HDFS数据。
正确使用方法: 如果所在机器已经部署好UHadoop客户端(部署方法请参考hadoopdev#在UHost上安装Hadoop客户端),可直接通过hadoop fs -ls / 或者hadoop fs -ls hdfs://Ucluster/访问
如果是客户端代码,可以将集群/home/hadoop/conf/hdfs-site.xml和/home/hadoop/conf/core-site.xml拷贝到本地程序中,通过conf.addResource加载2个文件,即可通过hdfs://Ucluster/访问HDFS数据
core节点由于要启动node-manager 服务,会存一部分本地数据。所以,会用到额外的空间。core1节点会被zookeeper和 jornal-node占用一部分空间。所以,会更少一点。标准是配置90%空间给HDFS。
slaves相当于一份白名单机制,如果不配置此文件,默认新加core节点可以直接加入集群;新加节点是通过读取hdfs-site.xml文件中的namenode相关信息找到并正确加入集群的,其他用户节点或者网络不通的节点是无法加入本集群的。
hbase的regionservers文件配置同理。
".Trash" 的文件默认配置是按5天check一次的,如果 ".Trash" 目录下的文件超过5天就会删除,如果没超过5天,这个文件会放到类似 "/.Trash/yyMMddHHmm" 命名的文件中,然后等待5天做下一次检查,这些文件才会被删除,因此 ".Trash" 文件会保存5-10天。
可以更改以下2个参数更改保存与check时间:
fs.trash.interval文件保存时间fs.trash.checkpoint.interval文件check时间,默认等于"fs.trash.interval"- 错误1:Could not load native gpl library
确认当前客户端配置和集群一样的环境变量 “LD_LIBRARY_PATH”
- 错误2:java.lang.RuntimeException: native-lzo library not available
这个错误是执行任务的机器没有安装lzo-devel,程序找不到liblzo2.so.2导致的,在该机器上执行如下命令安装即可:
yum install lzo lzo-devel为了便于管理,目前task节点必须保持统一的配置。
所以需要调整task节点配置的时候,只能通过删除现有的task节点后,选择新的类型。
注意: 1.删除task节点时,会影响到当前正在运行中的任务; 2.需要用户自行备份的删除节点上的数据。
为了易于管理资源和调度资源,Yarn内置了资源规整化算法,它规定了最小可申请资源量、最大可申请资源量和资源规整化因子,如果应用程序申请的资源量小于最小可申请资源量,则Yarn会将其大小改为最小可申请量,也就是说,应用程序获得资源不会小于自己申请的资源,但也不一定相等;如果应用程序申请的资源量大于最大可申请资源量,则会抛出异常,无法申请成功;规整化因子是用来规整化应用程序资源的,应用程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值,公式为ceil(a/b)*b,其中a是应用程序申请的资源,b为规整化因子。
以上介绍的参数需在yarn-site.xml中设置,相关参数如下:
- yarn.scheduler.minimum-allocation-mb:最小可申请内存量,默认是1024
- yarn.scheduler.minimum-allocation-vcores:最小可申请CPU数,默认是1
- yarn.scheduler.maximum-allocation-mb:最大可申请内存量,默认是8096
- yarn.scheduler.maximum-allocation-vcores:最大可申请CPU数,默认是4
对于规整化因子,不同调度器不同,具体如下:
- FIFO和Capacity Scheduler:规整化因子等于最小可申请资源量,不可多带带配置。
- Fair Scheduler:规整化因子通过参数yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores设置,默认是1024和1。
通过以上介绍可知,应用程序申请到资源量可能大于资源申请的资源量,比如YARN的最小可申请资源内存量为1024,规整因子是1024,如果一个应用程序申请1500内存,则会得到2048内存,如果规整因子是512,则得到1536内存。
如果上传的文件使用了压缩,并且有破损的时候,会导致执行的任务失败。可以通过查看任务的日志文件定位损坏的文件。
- 从web-yarn的界面找到出错的任务;
- 点击查看任务的详细信息;
- 打开任务的History链接,找到失败的Mapper;
- 查看具体失败的mapper处理的是哪一个文件。有两种方法可以避免这个问题:
- 如果这个文件对结果影响不大, 那么可以跳过这个错误。 可以通过交任务时指定mapreduce.map.skip.maxrecords来跳过这个错误,让任务可以继续下去;
- 使用其他的压缩格式。因为gzip压缩需要保持整个文件完整才能解压,推荐使用lzo格式,即使文件部分损坏,也可以保证任务继续运行。添加节点成功后,后台会自动进行数据均衡。如果长时间之后,集群的数据量还是不均衡,可以在“集群管理”页面提交数据均衡请求,如下图:
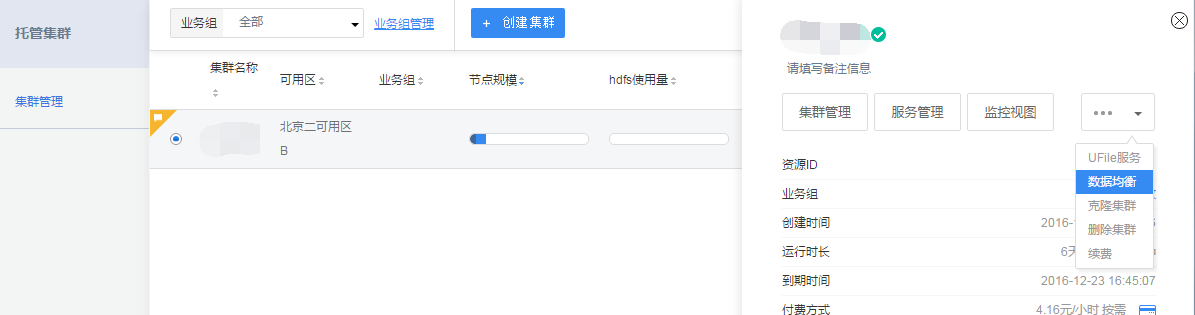
也可以在master节点提交均衡命令:
/home/hadoop/sbin/start-balancer.sh -threshold 10threshold是判断集群是否平衡的目标参数。默认值为10。表示当集群中所有core节点的可用磁盘容量百分比的差距小于10时,退出数据均衡。
因为在数据均衡的同时,也会有数据写入,可以在/home/hadoop/conf/hdfs-site.xml中修改数据均衡时可以占用的带宽:
<property>
<name>dfs.balance.bandwidthPerSecname>
<value>10485760value>
property>这面是设置传输速率为20M/S。
注意: 该值如果设置过大,可能会影响正常的hdfs读写和yarn任务执行。
如果发现hdfs读数据响应慢,出现
WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Slow BlockReceiver write data to disk cost可以从以下几个方面查找问题:
- 检查磁盘IO;
- 检查对于节点的GC情况;
- 检查网络带宽;HDFS 支持并发读、读写,但写入不能并发。有且仅有一个客户端时可同一时刻写某个文件,但多个客户端不能同时对HDFS写文件。这是由于当一个客户端获得NameNode的允许去写DataNode上的一个块时,这个块会被锁住,直到操作完成。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/126740.html

摘要:也可以将托管集群设置为快捷方式,通过左侧快捷方式菜单栏点击进入。框架集群中仅部署。用于做存储集群,有专属的节点机型。节点管理节点,负责协调整个集群服务。目前仅节点支持绑定。通过云主机内网进行登录。登录密码为集群创建时设置的密码。 快速上手本篇目录创建集群提交任务本文档将带领您如何创建UHadoop集群,并使用UHadoop集群完成数据处理任务。创建集群本章简单介绍了用户使用UHadoop服务...
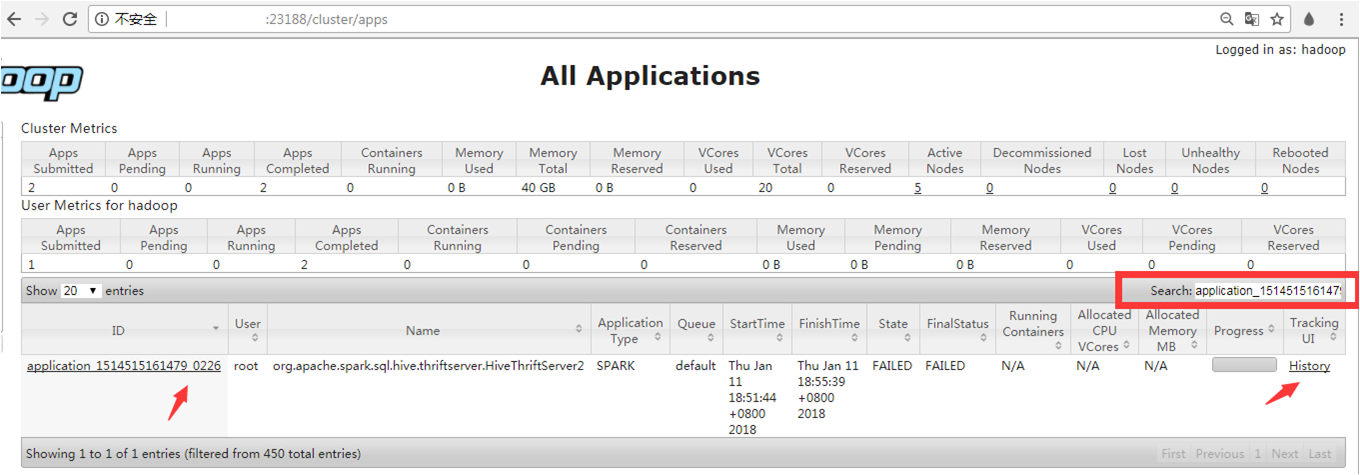
摘要:查看上的历史日志查看上的历史日志任务的日志在任务运行结束之后会上传到上,当日志文件过大无法通过来查看时,可以通过将日志文件从上下载下来查看。挂载在允许的主机上执行 常用操作本篇目录应用的Web接口查看日志配置NFS挂载hdfs到本地应用的Web接口Hadoop 提供了基于 Web 的用户界面,可通过它查看您的 Hadoop 集群。Web 服务会在主节点上运行(Active NameNode或...
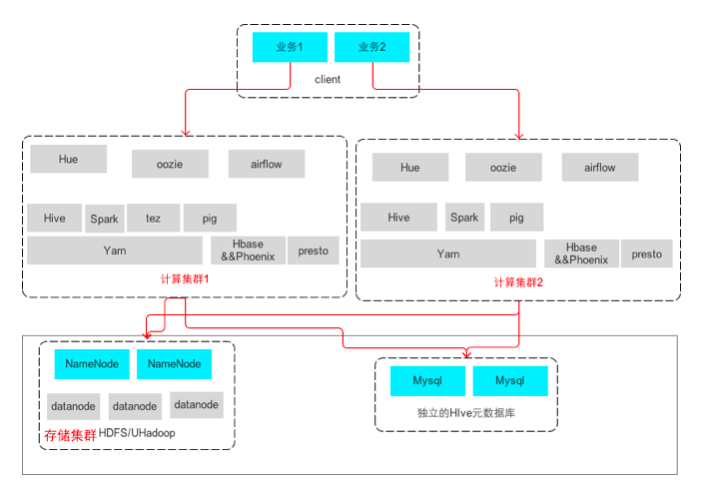
摘要:架构架构元数据管理元数据管理元数据管理创建集群时可在控制台开启元数据独立管理。若项目中已开启过元数据独立管理,则新集群开启该功能时,不再创建新的,而是将新集群的元数据存储于已有的中。 元数据管理本篇目录介绍产品架构元数据管理介绍UHadoop 支持将 Hive-Metastore 的数据库独立于 Hadoop 集群部署,也支持多个集群访问同一个 Hive 元数据库,可在控制台对其做管理。产品...
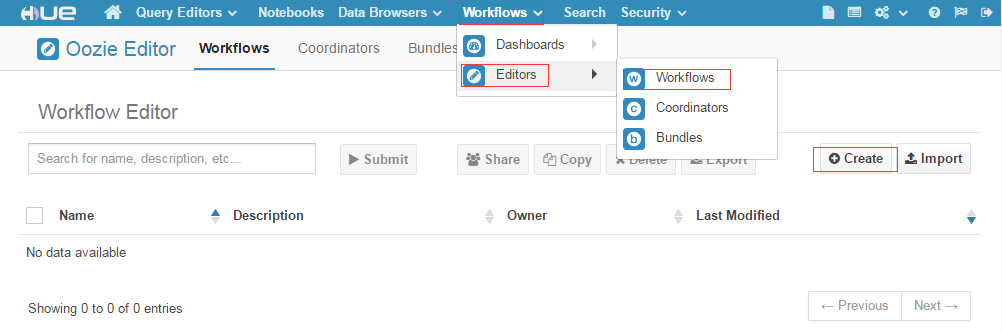
摘要:创建任务创建任务选择这个标签拖动到中。页面权限控制页面权限控制页面权限控制点击管理用户组选择要修改的组名称,设置相应权限并保存 Hue开发指南本篇目录1. 配置工作流2. Hue页面权限控制Hue是面向 Hadoop 的开源用户界面,可以让您更轻松地运行和开发 Hive 查询、管理 HDFS 中的文件、运行和开发 Pig 脚本以及管理表。服务默认已经启动,用户只需要配置外网IP,在防火墙中配...

摘要:执行语句时,任务内存不足怎么办执行语句时,任务内存不足怎么办执行语句时,任务内存不足怎么办如果在日志文件中看到出现错误,可以通过等来增大或可以使用的内存数。 Hive本篇目录Hive执行sql任务太慢,是否可以支持hive on spark?执行SQL语句时,map/reduce任务内存不足怎么办?hive-server2 通过jdbc提交任务的时候报文件权限不足执行sql时速度很慢怎么办?...

阅读 1272·2025-02-07 13:29
阅读 973·2024-11-07 18:25
阅读 131439·2024-02-01 10:43
阅读 1189·2024-01-31 14:58
阅读 1117·2024-01-31 14:54
阅读 83517·2024-01-29 17:11
阅读 3801·2024-01-25 14:55
阅读 2359·2023-06-02 13:36
