
摘要:普罗米修斯是谁在希腊神话中,是泰坦神族的神明之一,名字的意思是先见之明。普罗米修斯与智慧女神雅典娜共同创造了人类,普罗米修斯负责用泥土雕塑出人的形状,雅典娜则为泥人灌注灵魂,并教会了人类很多知识。
From Wikipedia:在希腊神话中,是泰坦神族的神明之一,名字的意思是“先见之明”。普罗米修斯与智慧女神雅典娜共同创造了人类,普罗米修斯负责用泥土雕塑出人的形状,雅典娜则为泥人灌注灵魂,并教会了人类很多知识。
Prometheus 是一个由 SoundCloud 公司开发并开源的监控和告警工具。主要功能包括监控指标的收集,存储,查询以及以此为基础的告警管理,其内部包含一个用来存储指标的单机时序数据库。它的开发受到了Google内部监控系统 Borgmon 的启发。
Borgman 的特点是不使用特定的脚本来判断系统是否正常工作,而是依靠一种标准数据分析模型进行报警。这使得批量、大规模、低成本的数据收集变得可能,而不需要执行复杂的子进程以及建立特殊的网络链接。
利用 Prometheus 和自动服务发现, 我们可以采用 pull mode 而不是 push mode 来收集服务的指标,pull mode 对于服务端的实现成本更低。
闲言:一个系统是采用 pull mode 还是 push mode 是很值得思考的问题。pull mode 的实现可能更简单,数据的提供方只需要被动的等待数据的需求方来拉取数据就可以了,减少了很多 sync 的工作,但是因为会在 pipeline 产生 bubble,性能可能会不好。而 push mode 会使 pipeline 开足马力运行,会带来更好的性能,但同时会增加系统设计的复杂度,比如 sync,retry 等工作。
Google SRE 这本书中介绍主要有四个原因:
同样来自 Google SRE 一书:
服务处理某个请求所需要的时间。需要区分成功请求和失败请求很重要。2
2.流量
使用系统中的某个高层次的指标针对系统负载进行的度量。
3.错误
请求失败的频率,可以是显示失败(例如HTTP 500),隐式失败(例如HTTP 200 但是包含了错误内容)或者是某种策略原因导致的失败(例如响应超时)
4.饱和度
衡量服务容量有多“满”,通常是系统中最为受限的某种资源的某个具体指标的度量(比如内存,IO)。
碎语:一本好书
Prometheus 将收集的监控指标数据作为时序数据进行存储,一条时序数据流(stream)由指标名称(metric name)和标签(label)以及被打赏时间戳的数据组成:
{ 例如用来记录一个 API 网关中注册的一台服务器的健康状态(1 代表健康):
api_gray_gateway_upstream_health{usptream="product-test",id="0",name="192.168.152.194:8000",backup="false"} 1
api_gray_gateway_upstream_health{usptream="product-test",id="1",name="192.168.152.195:8000",backup="false"} 0通过这种简单的数据模型我们可以组合出四种典型的指标类型。
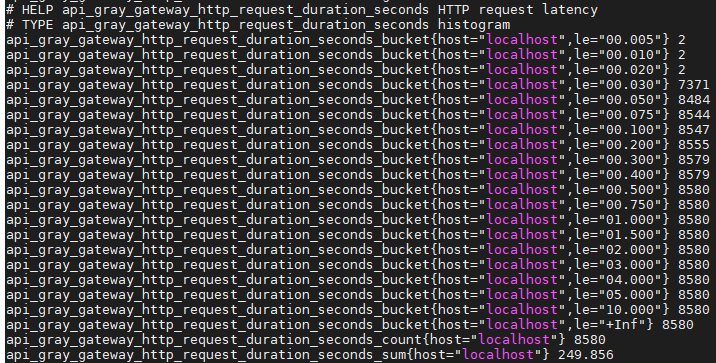
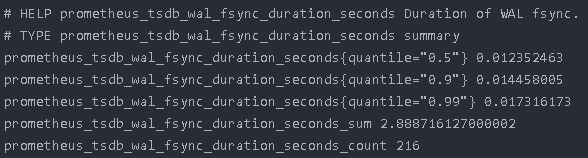
我们的 HTTP 网关是使用 OpenResty 实现的,具有良好的扩展性。实现这一特性,只需要在 /metrics 接口中增加查询后端服务器状态的逻辑(使用 lua-upstream-nginx-module 模块的 API),并使用Gauge 类型的指标记录健康状态,然后将结果返回给Prometheus,如:

最后在 Grafana 中(Prometheus作为数据源)建立图表,还可以通过设置一些变量方便业务方查询不同的 Upstream 中 Server 的健康状态,当然这里的图表还可以更美观一些(我用的 Grafana 版本有点老)并且集成到其他 WEB 页面中,下图中状态 1 表示 Server 健康,0 表示不健康。
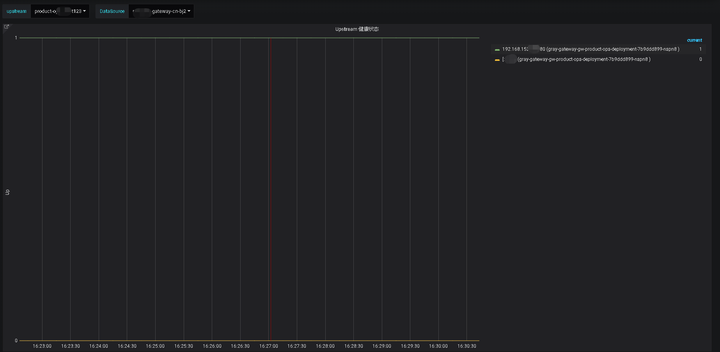
在这个应用中,我利用了 Prometheus 简单的编程模型和查询能力,以及 Grafana 的图表生成能力,快速构建了监控系统。
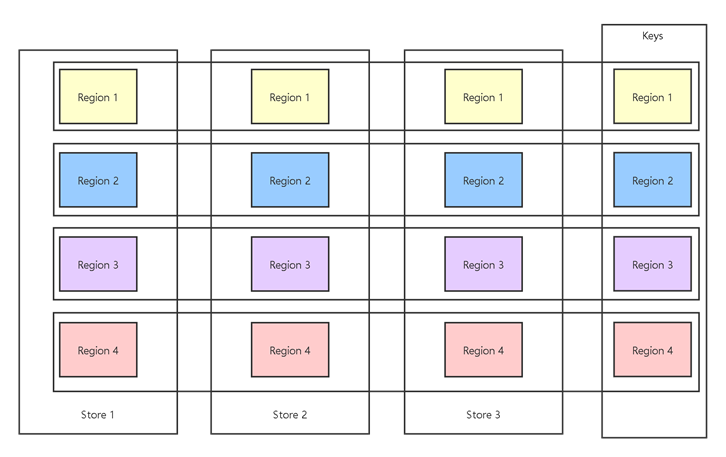
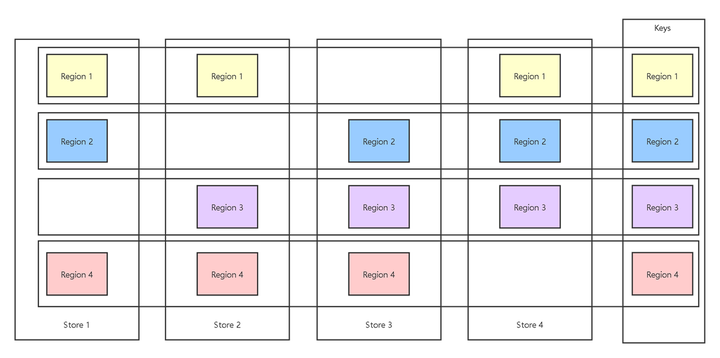
背景:TiDB 是一个由 Pingcap 公司主导的开源分布式 NewSQL 数据库,TiDB 使用 TiKV 作为存储。TiKV 一个由 Pingcap 公司主导的开源分布式 Key-value 数据库。Raft是 一个工业领域内常用的分布式一致性算法,而 TiKV 使用的正是 Raft 算法,更具体的是一种 Multi Raft Group。下图的示例中,每个 Store 是一个实际的存储节点(一个进程),因为性能的原因数据会分成多个 Region 存储(不同 Region 存储不同 Key 范围的数据),为了实现高可用同一个 Region 的数据在不同的 Store 中会有多个副本(Peer),同一个 Region 的不同 Peer 构成一个 Raft 共识:
当我们需要对系统进行扩容时,可以添加一个 Store,并由 PD (Placement Driver for TiKV)完成 Region 的 Peer 在 Store 中分布的调整。这些调整是在线调整的,如果 Peer 的迁移速度过快会影响系统的性能,因而需要对速度进行限制,PD 中采用了令牌桶算法实现了限速的特性。
为了监控限速模块的工作状态,需要设计一些监控指标。我在 https://github.com/pingcap/pd/pull/2404 这个 PR 中完成了对限速模块监控指标的改进。
改进后的指标有:
指标收集的时机:
这里我们需要关注的是需要根据指标的含义选择指标类型,需要合理利用不同指标类型,收集与之相适应的监控数据。
思考:在工作之余参与其他开源项目(比如 TiDB,Kubernetes)可以开拓视野,收获行业内的一些先进经验,避免思维的僵化。
本文介绍了 Prometheus 的特定,数据模型,指标类型以及监控指标设计方面的准则,以及一些闲言碎语。最后介绍了两个实际工作和业余参与的开源项目中的实际应用。
本文作者:
王任铮 UCloud 后台研发工程师
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/125985.html
摘要:有点基础的人一定都知道,命令会将源文件编译成字节码文件,即文件,其中就包含了大量的字节码指令。关于字节码指令的分类,可以从两个维度进行一是指令的功能,二是指令操作的数据类型。 前言 随着Java开发技术不断被推到新的高度,对于Java程序员来讲越来越需要具备对更深入的基础性技术的理解,比如Java字节码指令。不然,可能很难深入理解一些时下的新框架、新技术,盲目一味追新也会越来越感乏力。...
摘要:以后会持续更新,也欢迎各路前端大神交流技术。我想在前端的小路上走远一点,再远一点。 Welcome to my home Lycoris_cty ! 欢迎大家来我的FE小站。以后会持续更新,也欢迎各路前端大神交流技术。PS: 我想在前端的小路上走远一点,再远一点。Thanks!
摘要:根据配置文件,对接收到的警报进行处理,发出告警。在默认情况下,用户只需要部署多套,采集相同的即可实现基本的。通过将监控与数据分离,能够更好地进行弹性扩展。参考文档本文为容器监控实践系列文章,完整内容见 系统架构图 1.x版本的Prometheus的架构图为:showImg(https://segmentfault.com/img/remote/1460000018372350?w=14...

阅读 3651·2023-04-25 20:09
阅读 3818·2022-06-28 19:00
阅读 3177·2022-06-28 19:00
阅读 3212·2022-06-28 19:00
阅读 3308·2022-06-28 19:00
阅读 2970·2022-06-28 19:00
阅读 3201·2022-06-28 19:00
阅读 2752·2022-06-28 19:00






