
摘要:近两年,为什么都开始谈论起这个新名词了先说我的想法,其实还是用户需求驱动数据服务,大家开始关注的根本原因是用户需求发生了质变,过去的数据仓库模式以及涉及到的相关组件没有办法满足日益进步的用户需求。
近两年,为什么都开始谈论起 Data Lake 这个”新名词”了?
先说我的想法,其实还是用户需求驱动数据服务,大家开始关注 Data Lake 的根本原因是用户需求发生了质变,过去的数据仓库模式以及涉及到的相关组件没有办法满足日益进步的用户需求。
趋势
这里聊一个很重要的趋势:
数据实时化
当然这里有很多其他的趋势,比如低成本化、设计云原生化等,但总体上我还是认为数据实时化是近一两年来最热门、最明显且最容易让人看到收益的一个趋势。
数据仓库过去的模式大家可能都很了解,将整个数据仓库划分为 ODS、DWD、DWS,使用 Hive 作为数据存储的介质,使用 Spark 或者 MR 来做数据清洗的计算。这样的数据仓库设计很清晰,数据也比较容易管理,所以大家开开心心地使用这套理论和做法将近 10 年左右。
在这 10 年的时间里,主流的互联网公司在数据技术上的玩法并没有多大的改变,比如推荐需要用到的用户画像、电商里商品的标签、好友传播时用的图、金融风控数据体系,站在更高的一个角度看,我们会发现,十年前做的事情,比如用户画像表,如果你现在去做推荐服务,还是需要这个表。这样会产生一个什么现象?十年的互联网行业的人才积累、知识积累、经验积累,让我们可以更加容易地去做一些事情,比如十年前很难招聘到的懂推荐数据的人才,水平在如今也就是一个行业的平均值罢了。
既然这些事情变得更好做了,人才更多了,我们就期望在事情上做的更精致。因为从业务上讲,我去推荐短视频,让用户购买东西,这个需求是没有止境的,是可以永远做下去的。所以以前我可能是 T+1 才能知道用户喜欢什么,现在这个需求很容易就达到之后,我希望用户进来 10s 之后的行为就告诉我这个用户的喜好;以前可能做一些粗粒度的运营,比如全人群投放等,现在可能要转化思路,做更加精细化的运营,给每个用户提供个性化定制的结果。
技术演进1
数据实时化没问题,但是对应到技术上是什么情况呢?是不是我们要在实时领域也搭一套类似离线数据仓库的数据体系和模式?
是的,很多公司确实是将实时数据流划分为了不同层级,整体层级的划分思路和离线仓库类似,但是实时数据的载体就不是 Hive 或者 Hdfs 了,而是要选择更加实时的消息队列,比如 Kafka,这样就带来了很多问题,比如:
消息队列的存储时间有限
消息队列没有查询分析的功能
回溯效率比文件系统更差
除了实时数据载体的问题,还有引入实时数仓后,和离线数仓的统一的问题,
比如实时数仓的数据治理、权限管理,是不是要多带带做一套?
如何统一实时数据和离线数据的计算口径?
两套数据系统的资源浪费严重,成本提高?
举一个比较现实的例子,假设我们构造了一个实时计算指标,在发现计算错误后我们需要修正昨天的实时数据,这种情况下一般是另外写一个离线任务,从离线数仓中获取数据,再重新计算一遍,写入到存储里。这样的做法意味着我们在每写一个实时需求的同时,都要再写一个离线任务,这样的成本对于一个工程师是巨大的。
技术演进2
实时系统的成本太大了,这也是让很多公司对实时需求望而生畏的原因之一。所以这样去建设实时数仓的思路肯定不行啊,等于我要招两倍的人才(可能还不止),花两倍的时间,才能做一个让我的业务可能只提升 10% 的功能。从技术的角度来看,是这两套系统的技术栈不一样造成了工程无法统一。那么,Data Lake 就是用来解决这样一个问题,比如我一个离线任务,能不能既产生实时指标,也产生离线指标,类似下图这样:
除了计算层面上,在数据管理上,比如中间表的 schema 管理,数据权限管理,能否做到统一?在架构上实现统一后,我们在应对实时需求时,可以将实时离线的冗余程度降到最低,甚至能够做到几乎没有多余成本。
这块我们也在积极探索,国内互联网公司的主流做法还是停留在 【技术演进1】 的阶段,相信随着大家的努力,很快就会出现优秀且成功的实践。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/125909.html
摘要:数据湖通常更大,其存储成本也更为廉价。高存储成本数仓和数据湖都是为了降低数据存储的成本。数据停滞在数据湖中,数据停滞是一个最为严重的问题,如果数据一直无人治理,那将很快变为数据沼泽。数据湖(Data Lake),湖仓一体(Data Lakehouse)俨然已经成为了大数据领域最为火热的流行词,在接受这些流行词洗礼的时候,身为技术人员我们往往会发出这样的疑问,这是一种新的技术吗,还是仅仅只是概...
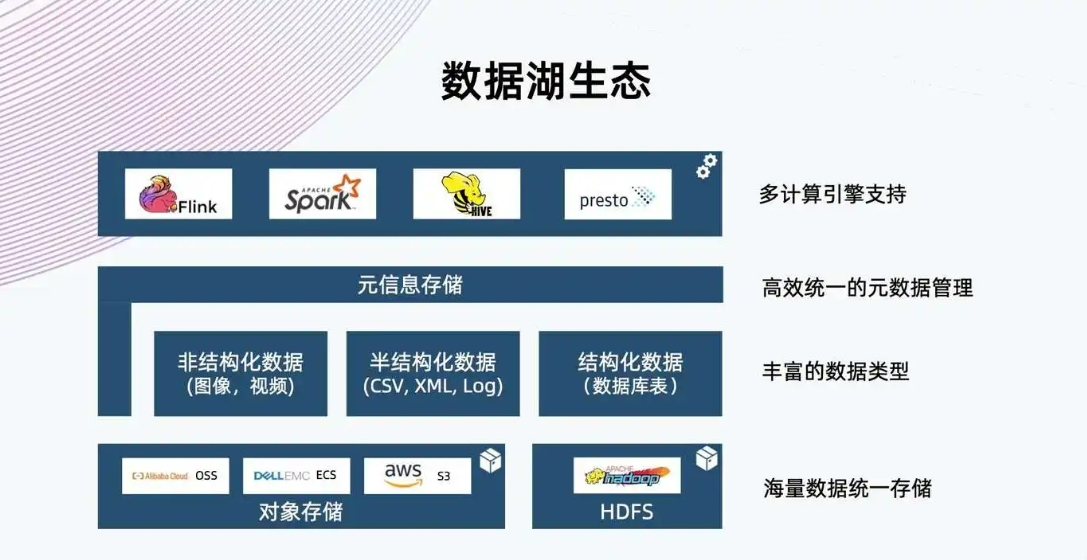
1、数据结构:数据仓库只能存储经过处理和提炼的数据,而数据湖存储尚未出于某种目的处理的原始数据。因此,数据湖需要比数据仓库大得多的存储容量,且数据灵活、分析迅速,非常适合机器学习。2、加工:数据仓库使用写入时序模式的方法来处理数据以赋予其形状和结构,而数据湖对原始数据使用读取模式来处理它。3、成本:存储在数据仓库中的成本可能很高,尤其是在有大量数据的情况下,而数据湖是专为低成本数据存储而设计,成本...
摘要:今天就我和大家来谈谈大数据领域的一些新变化新趋势。结语以上四个方面是数据科学在实践发展中提出的新需求,谁能在这些方面得到好的成绩,谁便会在这个大数据时代取得领先的位置。 从2012年开始,几乎人人(至少是互联网界)言必称大数据,似乎不和大数据沾点边都不好意思和别人聊天。从2016年开始,大数据系统逐步开始在企业中进入部署阶段,大数据的炒作逐渐散去,随之而来的是应用的蓬勃发展期,一些代表...
摘要:今天就我和大家来谈谈大数据领域的一些新变化新趋势。结语以上四个方面是数据科学在实践发展中提出的新需求,谁能在这些方面得到好的成绩,谁便会在这个大数据时代取得领先的位置。 从2012年开始,几乎人人(至少是互联网界)言必称大数据,似乎不和大数据沾点边都不好意思和别人聊天。从2016年开始,大数据系统逐步开始在企业中进入部署阶段,大数据的炒作逐渐散去,随之而来的是应用的蓬勃发展期,一些代表...

阅读 3645·2023-04-25 20:09
阅读 3812·2022-06-28 19:00
阅读 3175·2022-06-28 19:00
阅读 3209·2022-06-28 19:00
阅读 3301·2022-06-28 19:00
阅读 2967·2022-06-28 19:00
阅读 3192·2022-06-28 19:00
阅读 2751·2022-06-28 19:00




