
摘要:个假设领域内节点独立。参数的意义分别如下如果,那么采样会尽量不往回走,对应上图的情况,就是下一个节点不太可能是上一个访问的节点。如果,那么游走会倾向于在起始点周围的节点之间跑,可以反映出一个节点的特性。显示了当设置,时的示例。
论文题目:《node2vec Scalable Feature Learning for Network》
发表时间: KDD 2016
论文作者: Aditya Grover;Aditya Grover; Jure Leskovec
论文地址: Download
Github: Go
node2vec is an algorithmic framework for representational learning on graphs. Given any graph, it can learn continuous feature representations for the nodes, which can then be used for various downstream machine learning tasks.
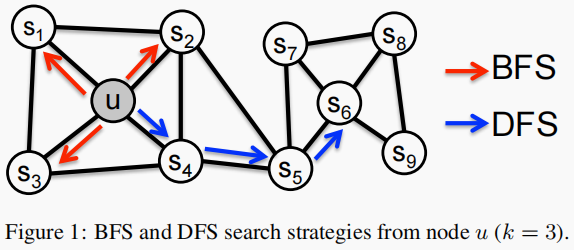
介绍传统方法的不足,以及本文采用的自然语言处理方法的介绍。
objective function:
$/underset{f}{max} /quad /sum /limits _{u /in V} /log /operatorname{Pr}/left(N_{S}(u) /mid f(u)/right) /quad /quad /quad /quad (1)$
2个假设
${/large /operatorname{Pr}/left(n_{i} /mid f(u)/right)=/frac{/exp /left(f/left(n_{i}/right) /cdot f(u)/right)}{/sum_{v /in V} /exp (f(v) /cdot f(u))}} $
总结上述两个假设得:
$/max _{f} /sum /limits_{u /in V}/left[-/log Z_{u}+/sum/limits_{n_{i} /in N_{S}(u)} f/left(n_{i}/right) /cdot f(u)/right]$
其中 $Z_{u}=/sum /limits _{v /in V} /exp (f(u) /cdot f(v))$ 。
推导过程:
${/large /begin{array}{l}/underset{f}{max} /sum /limits _{u /in V} /log P_{r}/left(N_{s}(u) /mid f(u)/right)///left.=/underset{f}{max} /sum /limits _{u /in V} /log /prod /limits_{n_{i} /in N_{s}(u)} P_{r}/left(n_{i}/right) f(u)/right)//=/underset{f}{max} /sum /limits_{u /in V} /sum /limits_{n_{i} /in N_{s}(u)} /log /frac{/operatorname{exp}/left(f/left(n_{i}/right) /cdot f(u)/right)}{/sum /limits_{V /in V} /exp (f(v) /cdot f(u))}//=/underset{f}{max} /left[-/sum /limits_{n_{i} /in N_{s}(u)} /log Z_{u}+/sum /limits_{n_{i} /in N_{s}(u)} f/left(n_{i}/right) f(u)/right]//=/underset{f}{max} /left[-/left|N_{s}(u)/right| /log Z_{u}+/sum /limits_{n_{i} /in N_{s}(u)} f/left(n_{i}/right) f(u)/right]/end{array}} $
推导过程中常数 $/left|N_{s}(u)/right|$ 忽略掉了,可能是因为这边采用了负采样策略,和邻居节点没有关系。
邻域 $N_{s}(u)$ 并不局限于近邻,但根据采样策略S,可以有很大不同的结构。
邻域 $N_{s}(u)$ 的大小固定为 $k$ ,使用不同的采样策略。这里提出两种采样策略:BFS and DFS。
DFS:邻域被限制为源的近邻节点。
在 Figure 1 中,假设 $k=3$, 则在 $u$ 的附近采样 node $s_{1}, s_{2}, s_{3}$。
BFS:邻域由距离源节点的距离顺序采样的节点组成。
在 Figure 1 中,假设 $k=3$, 则在 $u$ 的某路径上采样 node $s_{4}, s_{5}, s_{6}$。
基于上述观察结果,我们设计了一种灵活的邻域采样策略,使我们能够平滑地在 BFS 和 DFS 之间进行插值。我们通过开发一种灵活的 biased random walk 来实现这一点,该程序可以以 BFS 和 DFS 的方式探索社区。
形式上,给定一个源节点 $u$ ,我们模拟一个固定长度为 $l$ 的随机游动。设 $c_i$ 表示行走中的第 $i$ 个节点,以 $c_0=u$ 开始。节点 $c_i$ 由以下分布方式生成:
$P/left(c_{i}=x /mid c_{i-1}=v/right)=/left/{/begin{array}{ll}/frac{/pi_{v x}}{Z} & /text { if }(v, x) /in E //0 & /text { otherwise } /end{array}/right.$
其中 $/pi_{v x}$ 为节点 $v$ 和节点 $x$ 之间的非归一化转移概率,$Z$ 为归一化常数。
最简单的方法: $/pi_{v x}=w_{v x}$ ,对于无权图设置 $w_{v x} = 1$,对于有权图 $/pi_{v x}=w_{v x}$ 。
我们定义了一个具有两个参数 $p$ 和 $q$ 的二阶随机游走:
对于一个随机游走,如果已经采样了 $(t,v)$ ,即现在停留在节点 $v$ 上,那么下一个要采样的节点 $x$ 是?作者定义了一个概率分布,也就是一个节点到它的不同邻居的转移概率:
$/pi_{v x}=/alpha_{p q}(t, x) /cdot w_{v x}$
其中:
$/alpha_{p q}(t, x)=/left/{/begin{array}{ll}/frac{1}{p} & /text { if } d_{t x}=0 //1 & /text { if } d_{t x}=1 ///frac{1}{q} & /text { if } d_{t x}=2/end{array}/right.$
这里,$d_{tx}$ 表示节点 $t$ 和节点 $x$ 之间的最短路径距离。
$/alpha_{p q}(t, x)$ 解释如下:
参数 $p、q $ 的意义分别如下:
Return parameter p:
In-out parameter q:
当 $p=1,q=1$ 时,游走方式就等同于 DeepWalk 中的随机游走。

算法参数:graph $G$、dimension $d$、Walks per node $r$,Walk length $l$,Context size $k$ ,Return $p$、In-out $q$ 。
Step 6 中一条 $walk$ 的生成方式如下:
我们通常对涉及节点对而不是单个节点的预测任务感兴趣,即 link prediction 。这里定义一个 $g(u,v)$ 使用 $f(u)$ 和 $f(v)$ 来代表边的特征向量。


Figure 3(top)显示了当设置 $p=1,q=0.5$ 时的示例。不同网络社区使用不相同的颜色着色。在这个设置中,node2vec 发现了在小说的主要子情节中经常相互作用的角色集群/社区。由于字符之间的边缘是基于共现的,我们可以得出这一表征与同质性密切相关的结论。
为发现哪些节点具有相同的结构角色,我们使用相同的网络,但设置了 $p=1,q=2$,使用 node2vec 获得节点特征,然后根据所获得的特征对节点进行聚类。在这里, node2vec 获得了一个节点对簇的互补分配,这样颜色就对应于结构的等价性,如 Figure 3(bottom)所示。例如, node2vec 将蓝色的节点嵌入在一起。这些节点代表了小说中不同子情节之间的桥梁。类似地,黄色节点主要代表位于外围且交互作用有限的字符。我们可以为这些节点集群分配替代的语义解释,但关键的结论是, node2vec 并不与特定的等价概念绑定。正如我们通过实验所表明的,这些等价的概念通常在大多数现实世界的网络中表现出来,并对预测任务的学习表示的性能有重大影响。
我们的实验评估了通过 node2vec 在标准监督学习任务上获得的特征表示:multilabel classification for nodes and link prediction for edges。对于这两项任务,我们根据以下特征学习算法来评估 node2vec 的性能:
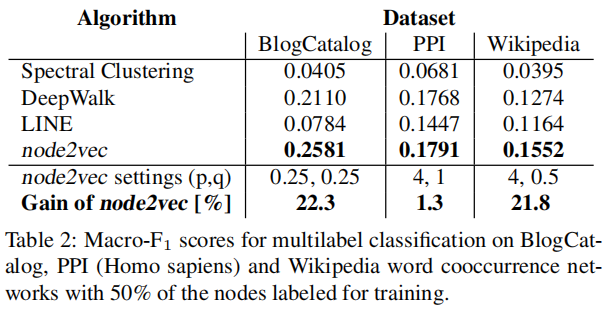
具体来说,我们设置了 $d=128 , r=10 , l=80 , k=10$,并在一个 epoch 中进行优化。我们使用 10 个随机种子初始化重复实验。对 10%标记数据进行 $ p、q∈{0.25、0.50、1、2、4}$ 网格搜索的 10-fold cross-validation ,学习最佳 $p$ 和 $q$。
Node feature representations 被输入到一个 L2 regularization 的 one-vs-rest logistic regression classifier 上。我们使用 $Macro-F1 scores$ 作为评价标准。
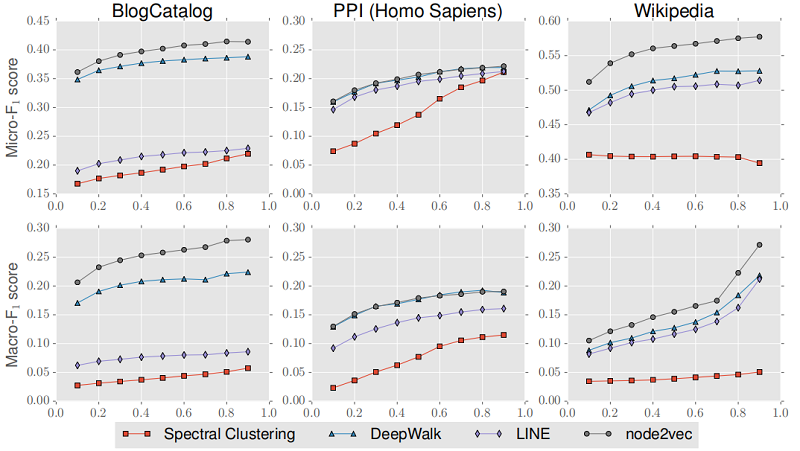
对于更多的 fine-grained analysis,我们还比较了性能,同时将 $train-test split$ 从 $10%$ 改变到 $90%$ ,学习参数 $p$ 和 $q$ 在 $10%$ 的数据进行分析。在 Figure 4 中总结了 Micro-F1 和 Macro-F1 score 的结果。
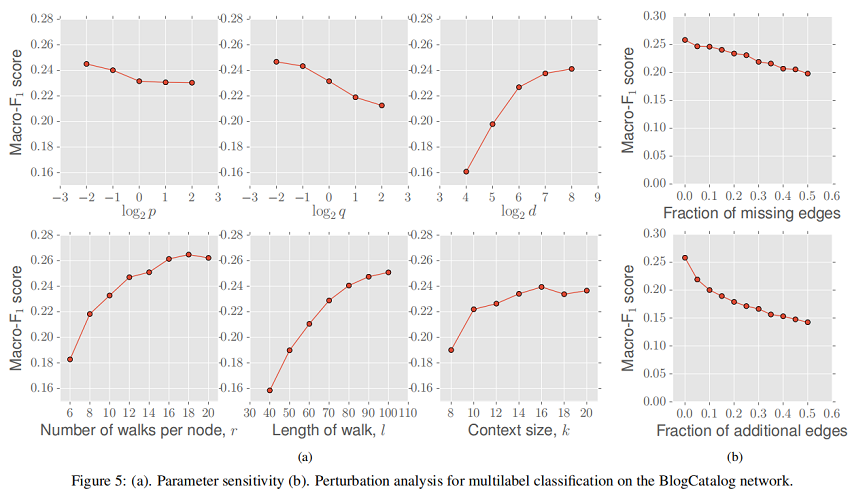
在第一种情况下,我们研究 missing edges 比列对性能的影响(相对于完整的网络)。缺失边是随机选择的,受网络中连接组件数量保持固定的约束。如图我们可以在Figure 5 b(top)中看到,随着缺边比列的增加,Macro-F1 分数大致呈线性下降,斜率较小。在图随着时间的推移而演化(例如引文网络)或网络构建昂贵(例如生物网络)时,对网络中缺失边缘的鲁棒性尤为重要。
在第二个扰动设置中,我们在网络中随机选择的节点对之间有噪声的边。如 Figure 5 b(bottom)所示,与 missing edges 的设置相比,node2vec 的性能最初下降的速度略快,但Macro-F1评分的下降速度随着时间的推移逐渐减慢。同样,node2vec 对 false edges 的鲁棒性在一些情况下是有用的,如传感器网络,用于构建网络的测量值是有噪声的。
为了测试可伸缩性,我们使用 node2vec 学习节点表示,并使用 Erdo-Renyi Graph 的默认参数,Node 数量从 100 个节点增加到 1000,000 个节点,平均度设置为10 不变 。实验如下:
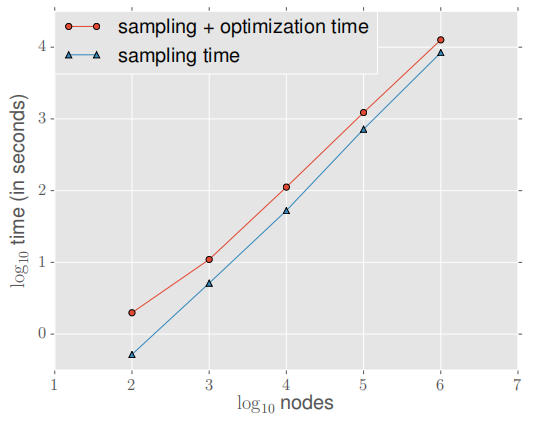
采样过程包括计算随机游走的 transition probabilities(可忽略的小)和模拟随机游走的预处理。
在链路预测中,我们给出了一个去掉一定比例边的网络,并且我们想预测这些缺失的边。
We generate the labeled dataset of edges as follows: To obtain positive examples, we remove 50% of edges chosen randomly from the network while ensuring that the residual network obtained after the edge removals is connected, and to generate negative examples, we randomly sample an equal number of node pairs from the network which have no edge connecting them.
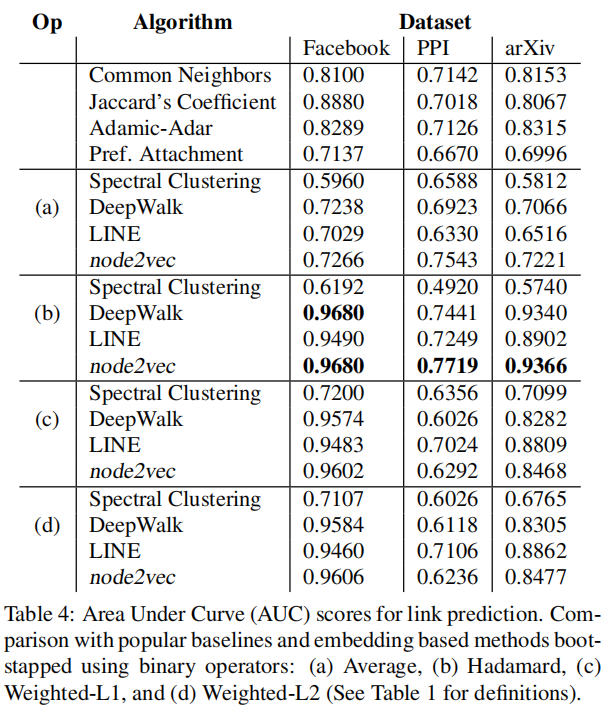
我们所考虑的分数是根据构成这对节点的节点的邻域集来定义的(Table 3)。

实验结果:
『总结不易,加个关注呗!』

Datasets
Links to datasets used in the paper:
因上求缘,果上努力~~~~ 作者:希望每天涨粉,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15601261.html
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/125377.html
摘要:调研首先要确定微博领域的数据,关于微博的数据可以这样分类用户基础数据年龄性别公司邮箱地点公司等。这意味着深度学习在推荐领域应用的关键技术点已被解决。 当2012年Facebook在广告领域开始应用定制化受众(Facebook Custom Audiences)功能后,受众发现这个概念真正得到大规模应用,什么叫受众发现?如果你的企业已经积累了一定的客户,无论这些客户是否关注你或者是否跟你在Fa...
摘要:首先第一种当然是在年提出的,它奠定了整个卷积神经网络的基础。其中局部感受野表示卷积核只关注图像的局部特征,而权重共享表示一个卷积核在整张图像上都使用相同的权值,最后的子采样即我们常用的池化操作,它可以精炼抽取的特征。 近日,微软亚洲研究院主办了一场关于 CVPR 2018 中国论文分享会,机器之心在分享会中发现了一篇非常有意思的论文,它介绍了一种新型卷积网络架构,并且相比于 DenseNet...
摘要:机器学习和深度学习的研究进展正深刻变革着人类的技术,本文列出了自年以来这两个领域发表的最重要被引用次数最多的篇科学论文,以飨读者。注意第篇论文去年才发表要了解机器学习和深度学习的进展,这些论文一定不能错过。 机器学习和深度学习的研究进展正深刻变革着人类的技术,本文列出了自 2014 年以来这两个领域发表的最重要(被引用次数最多)的 20 篇科学论文,以飨读者。机器学习,尤其是其子领域深度学习...

阅读 830·2023-04-25 19:43
阅读 4080·2021-11-30 14:52
阅读 3907·2021-11-30 14:52
阅读 3997·2021-11-29 11:00
阅读 3894·2021-11-29 11:00
阅读 4017·2021-11-29 11:00
阅读 3730·2021-11-29 11:00
阅读 6450·2021-11-29 11:00




