
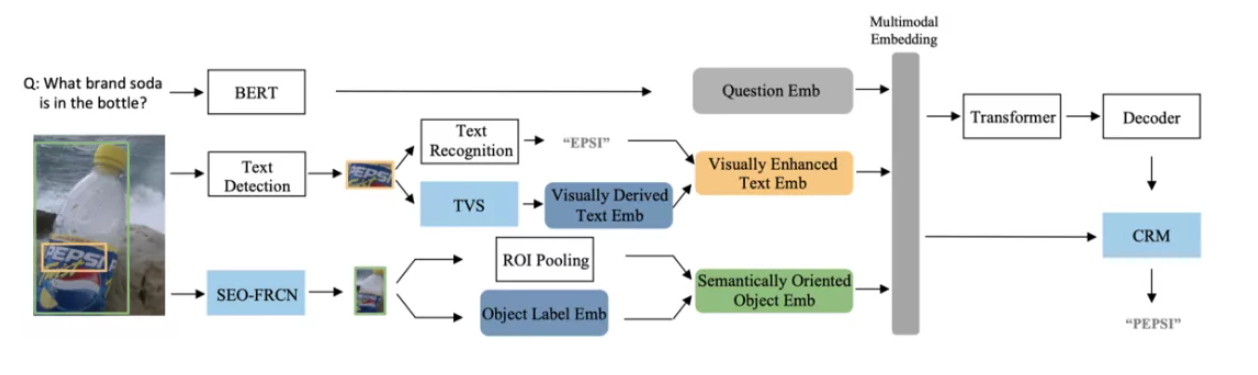
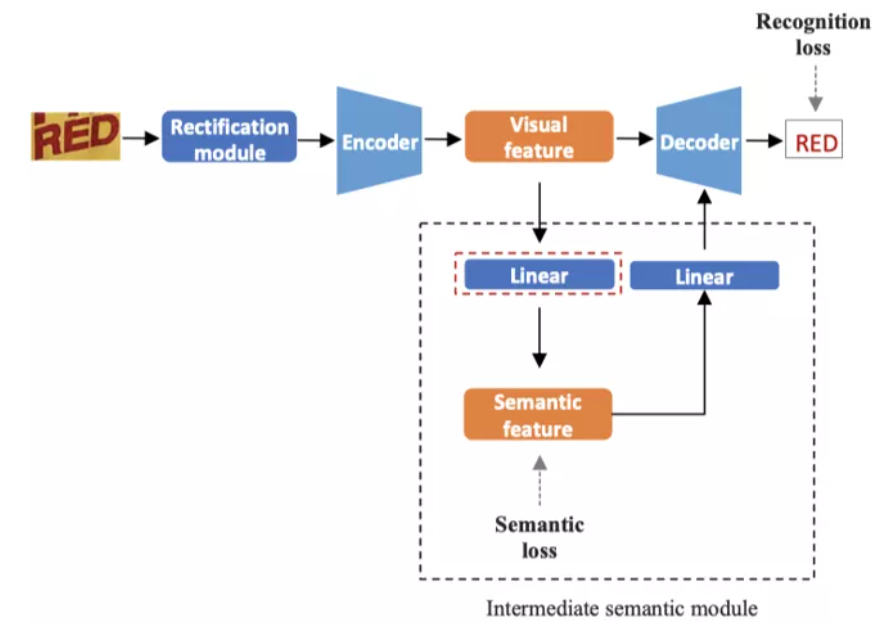
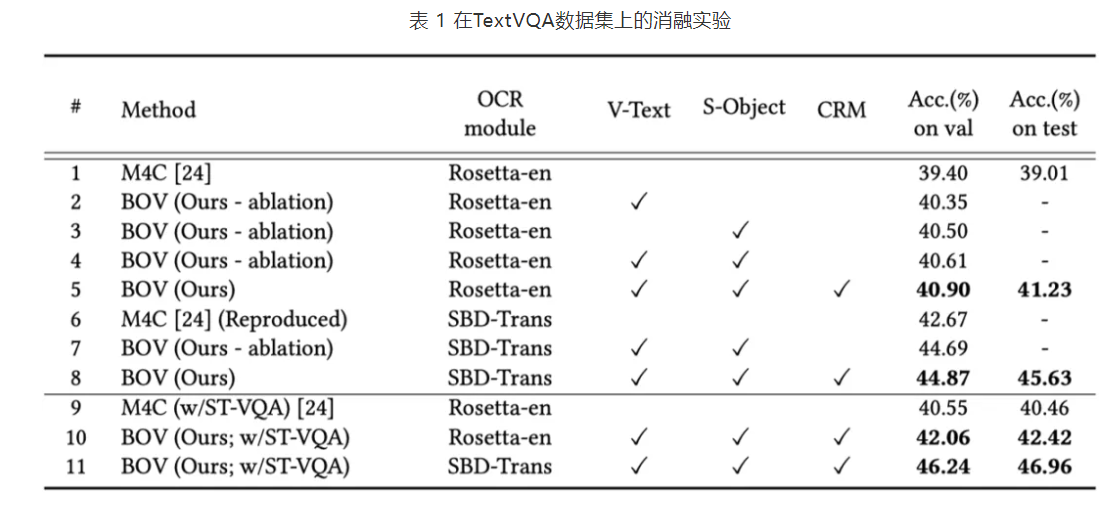
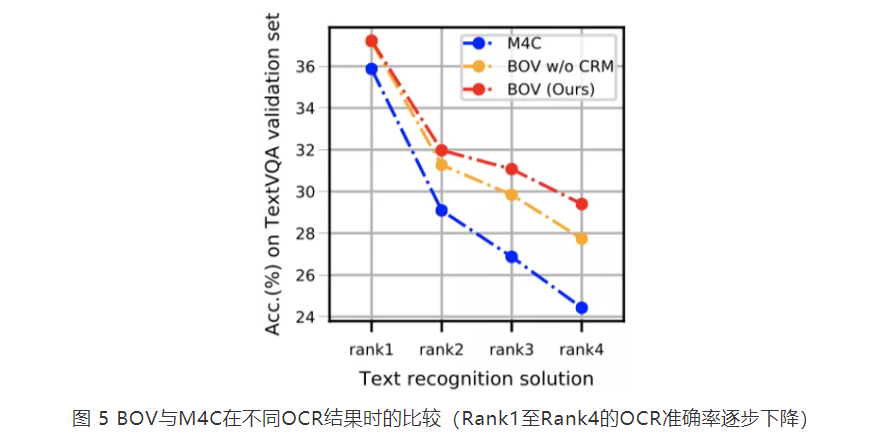
摘要:模块基于预训练模型进行识别,识别出的结果与一起经过注意力机制得到加权的空间注意力,得到的结果与进行组合。五六结论将融入的前向处理流程,构建了一个鲁棒且准确的模型参考博客
论文题目:Beyond OCR + VQA: Involving OCR into the Flow for Robust and Accurate TextVQA
论文链接:https://dl.acm.org/doi/abs/10.1145/3474085.3475606
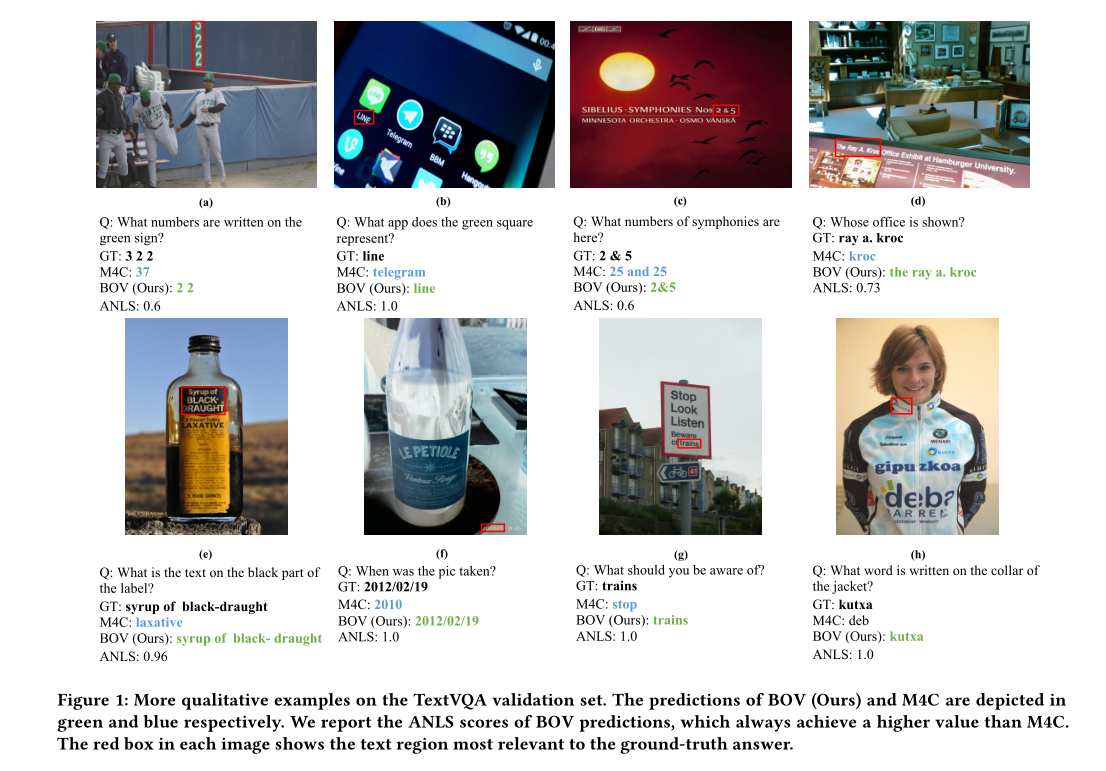
![]()
![]()
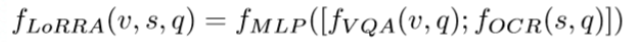
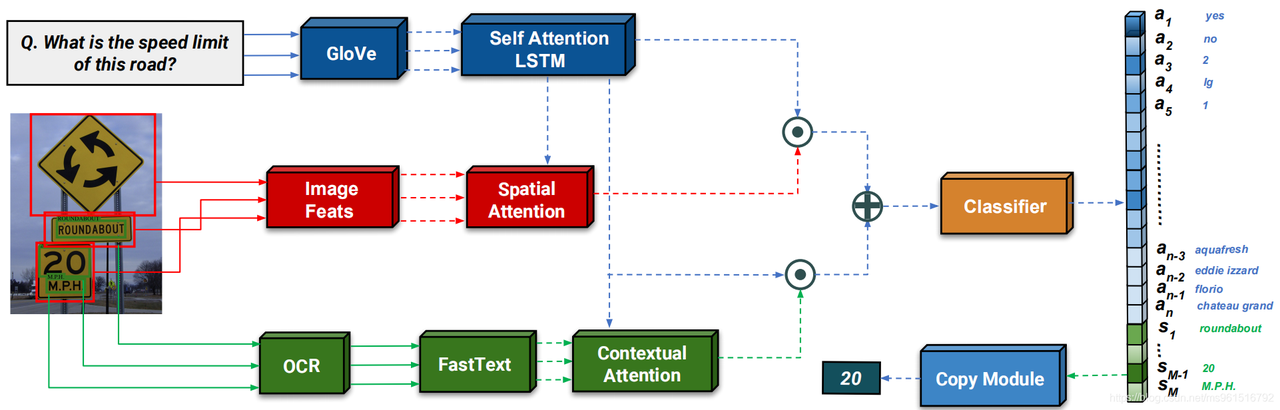
![]()
![]()

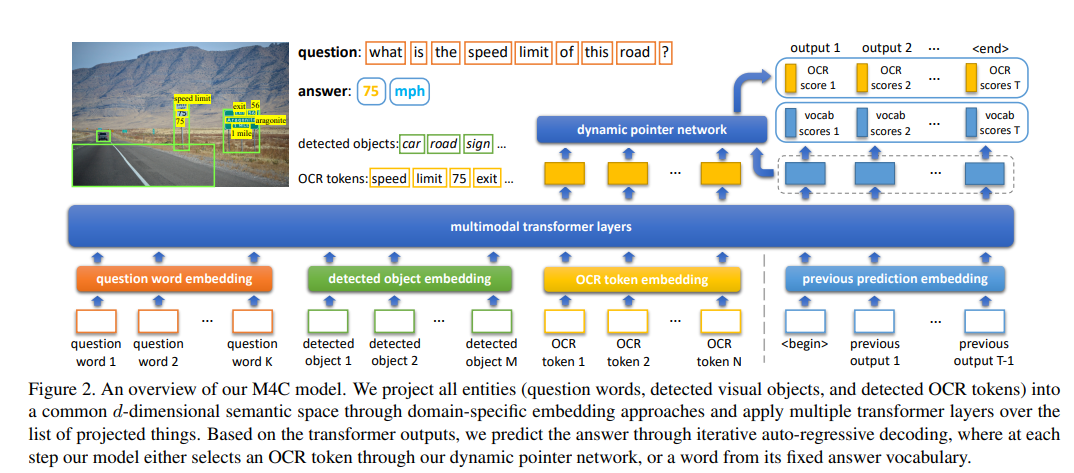
![]()
![]()

文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/125370.html
摘要:因为深度学习的正统观念在该领域已经很流行了。在机器和深度学习空间中进行的大多数数学分析倾向于使用贝叶斯思想作为参数。如果我们接受了目前深度学习的主流观点任何一层的微分都是公平的,那么或许我们应该使用存储多种变体的复分析。 深度学习只能使用实数吗?本文简要介绍了近期一些将复数应用于深度学习的若干研究,并指出使用复数可以实现更鲁棒的层间梯度信息传播、更高的记忆容量、更准确的遗忘行为、大幅降低的网...

阅读 3945·2023-01-11 11:02
阅读 4433·2023-01-11 11:02
阅读 3319·2023-01-11 11:02
阅读 5356·2023-01-11 11:02
阅读 4913·2023-01-11 11:02
阅读 5812·2023-01-11 11:02
阅读 5531·2023-01-11 11:02
阅读 4339·2023-01-11 11:02


