
摘要:完整代码火狐浏览器驱动下载链接提取码双十一刚过,想着某宝的信息看起来有些少很难做出购买决定。
完整代码&火狐浏览器驱动下载链接:https://pan.baidu.com/s/1pc8HnHNY8BvZLvNOdHwHBw 提取码:4c08
双十一刚过,想着某宝的信息看起来有些少很难做出购买决定。于是就有了下面的设计:
既然有了想法那就赶紧说干就干趁着双十二还没到
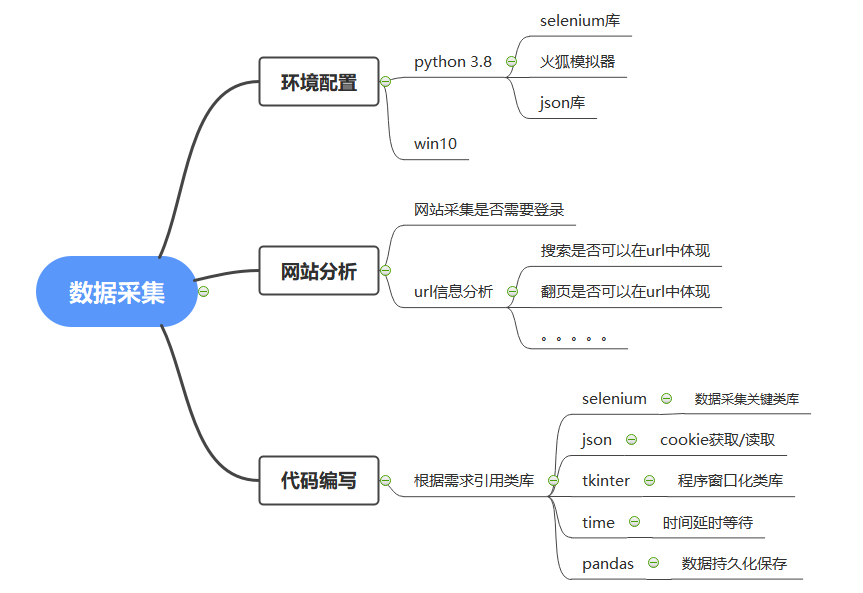
一、准备工作:
安装 :selenium 和 tkinter
pip install selenium
pip install tkinter
下载火狐浏览器驱动
二、网站分析
发现web端如果不登录就不能进行查找商品
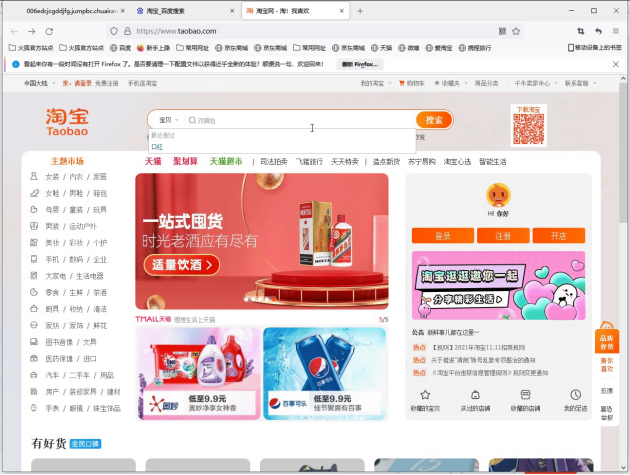
登录后查找口红
发现url竟然张这样
https://s.taobao.com/search?q=口红&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20211117&ie=utf8&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s=44
通过观察发现url中的q=**表示的是搜索的内容 s=**表示页数
接下来确定网页中我们将要采集的数据
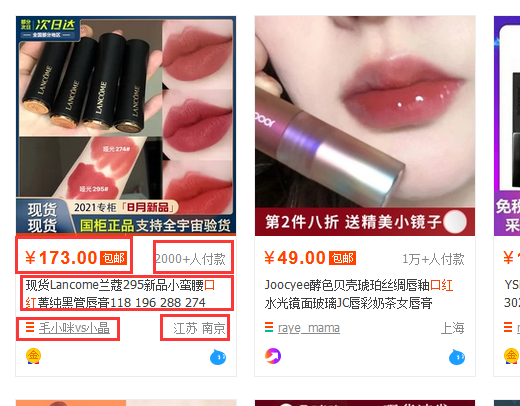
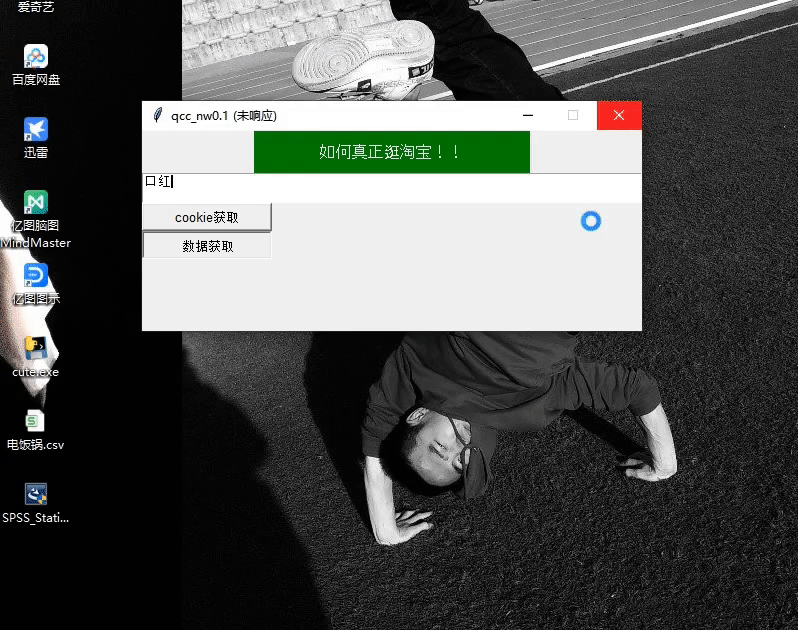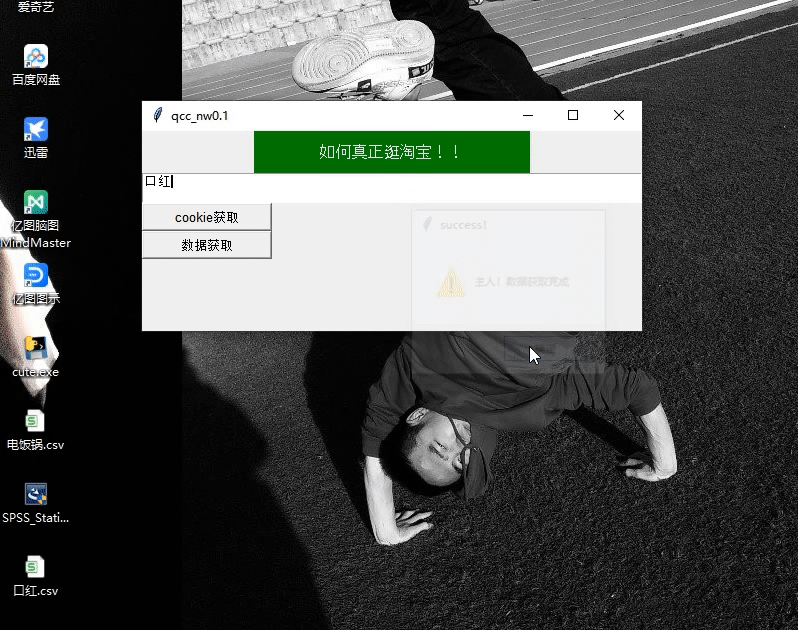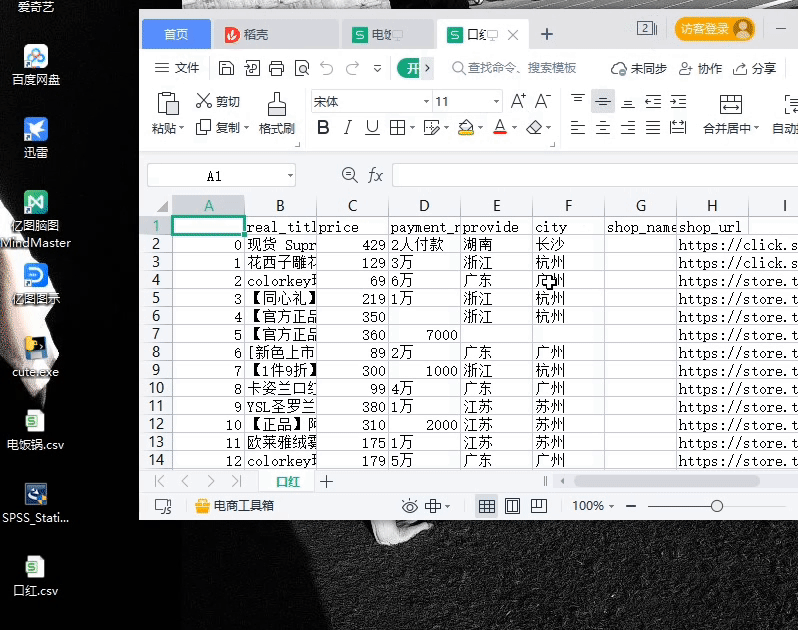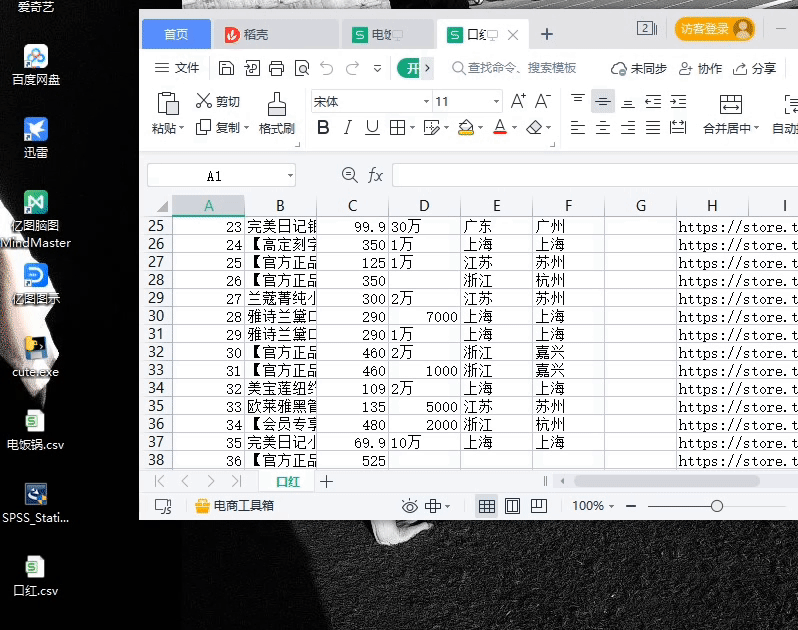
采集的数据有:商品价格;付款人数;商品标题;店铺url;店家地址;
三、代码编写
1、类库引用
import jsonimport pandas as pdfrom selenium import webdriverimport timefrom tkinter import *import tkinter.messagebox
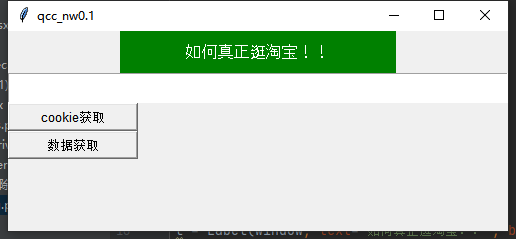
2、窗口化代码实现
# 设置窗口window = Tk()window.title(qcc_nw0.1)# 设置窗口大小window.geometry(500x200)# lable标签l = Label(window, text=如何真正逛淘宝!!, bg=green, fg=white, font=(Arial, 12), width=30, height=2)l.pack()# 输入要查询的宝贝的文本框E1 = Text(window,width=100,height=2)E1.pack()def get_cookie():passdef get_data():pass# cookie获取按钮cookie = Button(window, text=cookie获取, font=(Arial, 10), width=15, height=1,ommand=get_cookie)# 数据开按钮data = Button(window, text=数据获取, font=(Arial, 10), width=15, height=1,ommand=get_data)cookie.pack(anchor=nw)data.pack(anchor=nw)window.mainloop()
3、免登陆功能实现
对已经登录网站的cookie获取
def get_cookie():# 新建浏览器dirver = webdriver.Firefox()dirver.get(https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fbuyertrade.taobao.com%2Ftrade%2Fitemlist%2Flist_bought_items.htm%3Fspm%3D875.7931836%252FB.a2226mz.4.66144265Vdg7d5%26t%3D20110530)# 设置登录延时获取cookietime.sleep(20)# 直接用手机扫码登陆淘宝即可获取dictCookies = dirver.get_cookies()# 登录完成后,将cookies保存到本地文件jsonCookies = json.dumps(dictCookies)with open("cookies_tao.json", "w") as fp:fp.write(jsonCookies)
读取获取后的cookie实现登录效果:
1)先对selenium使用的模拟浏览器进行下伪装设置否则会被检测
def get_data():options = webdriver.FirefoxOptions()profile = webdriver.FirefoxProfile()ua = Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36profile.set_preference(general.useragent.override, ua)#UA伪装profile.set_preference("dom.webdriver.enabled", False) # 设置非driver驱动profile.set_preference(useAutomationExtension, False) # 关闭自动化提示profile.update_preferences() # 更新设置browser = webdriver.Firefox(firefox_profile=profile, firefox_options=options)
2)读取获取到的cookie实现免登陆
# 删除原有的cookiebrowser.delete_all_cookies()with open(cookies_tao.json, encoding=utf-8) as f:listCookies = json.loads(f.read())# cookie 读取发送for cookie in listCookies:# print(cookie)browser.add_cookie({domain: .taobao.com, # 此处xxx.com前,需要带点name: cookie[name],value: cookie[value],path: /,expires: None})
4、解析网页进行数据获取
# 获取输入框中的信息thing =E1.get(1.0,end)# 设置将要采集的URL地址url= "https://s.taobao.com/search?q=%s"# 设置采集的商品名称browser.get(url%thing)# 窗口最小化browser.minimize_window()# 获取商品总页数page_count = browser.find_element_by_xpath(/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[1]).textpage_count = int(page_count.split( )[1])# 设置接收字典dic = {real_title:[],price:[],payment_num:[],provide:[],city:[],shop_name:[],shop_url:[]}# 循环翻页设置for i in range(page_count):page = i*44browser.get(url%thing + &s=%d%page)div_list = browser.find_elements_by_xpath(//div[@class="ctx-box J_MouseEneterLeave J_IconMoreNew"])# 循环遍历商品信息for divs in div_list:# 商品标题获取real_title = divs.find_element_by_xpath(.//div[@class="row row-2 title"]/a).text# 商品价格获取price = divs.find_element_by_xpath(.//div[@class="price g_price g_price-highlight"]/strong).text# 商品付款人数获取payment_num = divs.find_element_by_xpath(.//div[@class="deal-cnt"]).text# 店家地址获取location = divs.find_element_by_xpath(.//div[@class="row row-3 g-clearfix"]/div[@class="location"]).text# 店家名称获取shop_name = divs.find_element_by_xpath(.//div[@class="row row-3 g-clearfix"]/div[@class="shop"]/a/span).text# 店家URL获取shop_url = divs.find_element_by_xpath(.//div[@class="row row-3 g-clearfix"]/div[@class="shop"]/a).get_attribute(href)# 判断地址是否为自治区或直辖市if len(location.split( ))>1:provide=location.split( )[0]city=location.split( )[1]else:provide=location.split( )[0]city = location.split( )[0]# 将采集的数据添加至字典中dic[real_title].append(real_title)dic[price].append(price)dic[payment_num].append(payment_num.replace(+人付款,))dic[provide].append(provide)dic[city].append(city)dic[shop_name].append(shop_name)dic[shop_url].append(shop_url)print(real_title,price,payment_num.replace(+人付款,),provide,city,shop_name,shop_url)# 使用pandas将获取的数据写入csv文件持久化存储df=pd.DataFrame(dic)df.to_csv(C:/Users/admin/Desktop/+thing.strip(/n)+.csv)browser.close()
截止至此基本完成
发现这样的数据写入是不会保存的所以要添加一个提示框来终止get_data函数的运行
def warning():# 弹出对话框result = tkinter.messagebox.showinfo(title = success!,message=主人!数据获取完成)# 返回值为:ok
在get_data函数中嵌套warning函数.
-----完活下班!!!!-----
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/123769.html
摘要:且本小白也亲身经历了整个从小白到爬虫初入门的过程,因此就斗胆在上开一个栏目,以我的图片爬虫全实现过程为例,以期用更简单清晰详尽的方式来帮助更多小白应对更大多数的爬虫实际问题。 前言: 一个月前,博主在学过python(一年前)、会一点网络(能按F12)的情况下,凭着热血和兴趣,开始了pyth...
摘要:时间永远都过得那么快,一晃从年注册,到现在已经过去了年那些被我藏在收藏夹吃灰的文章,已经太多了,是时候把他们整理一下了。那是因为收藏夹太乱,橡皮擦给设置私密了,不收拾不好看呀。 ...
摘要:然而让虫师们垂涎的并不是以上的种种,而是其通过驱动浏览器获得的解析的能力。所以说这货在动态爬取方面简直是挂逼级别的存在,相较于手动分析更简单易用,节省分析打码时间。一旦设置了隐式等待时间,它的作用范围就是对象实例的整个生命周期。 selenium——自动化测试工具,专门为Web应用程序编写的一个验收测试工具,测试其兼容性,功能什么的。然而让虫师们垂涎的并不是以上的种种,而是其通过驱动浏...
摘要:是一款优秀的自动化测试工具,所以现在采用进行半自动化爬取数据,支持模拟登录淘宝和自动处理滑动验证码。编写思路由于现在大型网站对工具进行检测,若检测到,则判定为机器人,访问被拒绝。以开头的在中表示类名,以开头的在中表示名。 简介 模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网站的升级,采取该策略比较难实现了...
摘要:简介现在爬取淘宝,天猫商品数据都是需要首先进行登录的。把关键点放在如何爬取天猫商品数据上。是一款优秀的自动化测试工具,所以现在采用进行半自动化爬取数据。以开头的在中表示类名,以开头的在中表示名。 简介 现在爬取淘宝,天猫商品数据都是需要首先进行登录的。上一节我们已经完成了模拟登录淘宝的步骤,所以在此不详细讲如何模拟登录淘宝。把关键点放在如何爬取天猫商品数据上。 过去我曾经使用get/p...

阅读 830·2023-04-25 19:43
阅读 4080·2021-11-30 14:52
阅读 3907·2021-11-30 14:52
阅读 3997·2021-11-29 11:00
阅读 3894·2021-11-29 11:00
阅读 4017·2021-11-29 11:00
阅读 3730·2021-11-29 11:00
阅读 6451·2021-11-29 11:00






