
摘要:如果截断长度为,位置编码的,下图是的在中给出了一种新的相对位置编码,几乎是和经典的绝对位置编码一一对应。只是把绝对位置编码替换成相对位置编码,在两个任务上都有的效果提升,最终效果也基本和一致。
这一章我们主要关注transformer在序列标注任务上的应用,作为2017年后最热的模型结构之一,在序列标注任务上原生transformer的表现并不尽如人意,效果比bilstm还要差不少,这背后有哪些原因? 解决这些问题后在NER任务上transformer的效果如何?完整代码详见ChineseNER
Hang(2019)在TENER的论文中给出了两点原因
1. 三角函数绝对位置编码只考虑距离没有考虑方向
2. 距离表达在向量project以后也会消失
我们先来回顾下原生Transformer的绝对位置编码, 最初编码的设计是为了满足几个条件
于是便有了基于三角函数的编码方式,在pos位置,维度是/(d_k/)的编码中,第i个元素的计算如下
基于三角函数的绝对位置编码是常数,并不随模型更新。在Transformer中,位置编码会直接加在词向量上,输入的词向量Embedding是E,在self-attention中Q,K进行线性变换后计算attention,对value进行加权得到输出如下
我们来对/(q_ik_j/)部分进行展开可以得到
其中位置交互是唯一可能包含相对位置信息的部分,如果不考虑线性变换/(w_k/),/(w_q/)只看三角函数位置编码,会发现位置编码内积是相对距离的函数,如下
不同维度/(d_k/),/(P_iP_j^T/)和/(/Delta/)的关系如下,会发现位置编码内积是对称并不包含方向信息,而BiLSTM是可以通过双向LSTM引入方向信息的。对于需要全局信息的任务例如翻译,sentiment analysis,方向信息可能并不十分重要,但对于局部优化的NER任务,因为需要判断每个token的类型,方向信息的缺失影响更大。
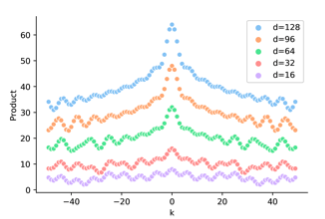
看完三角函数部分,我们把线性变换加上,下图是加入随机线性变换后/(P_iw_iw_j^TP_j^T/)和/(/Delta/)的关系,会发现位置编码的相对距离感知消失了,有人会问那这位置编码有啥用,这是加了个寂寞???

个人感觉上图的效果是加入随机变换得到,而/(W_i,W_j/)本身是trainable的,所以如果相对距离信息有用,/(W_iW_j^T/)未必学不到,这里直接用随机/(W_i/)感觉并不完全合理。But Anyway这两点确实部分解释了原生transformer在NER任务上效果打不过BiLSTM的原因。下面我们来看下基于绝对位置编码的缺陷,都有哪些改良
既然相对位置信息是在self-attention中丢失的,最直观的方案就是显式的在self-attention中把相对位置信息加回来。相对位置编码有很多种构建方案,这里我们只回顾TENER之前相对经典的两种(这里参考了苏神的让研究人员绞尽脑汁的Transformer位置编码再一次膜拜大神~)。为了方便对比,我们把经典的绝对位置编码计算的self-attenion展开再写一遍
(shaw et al,2018) 提出的RPR可以说是相对位置编码的起源,计算也最简单,只保留了以上Attention的语义交互部分,把key的绝对位置编码,替换成key&Query的相对位置编码,同时在对value加权时也同时引入相对位置,得到如下
这里/(R_{ij}/)是query第i个字符和key/value第j个字符之间的相对距离j-i的位置编码,query第2个字符和key第4个字符交互对应/(R_{-2}/)的位置编码。这样的编码方式直接考虑了距离和方向信息。
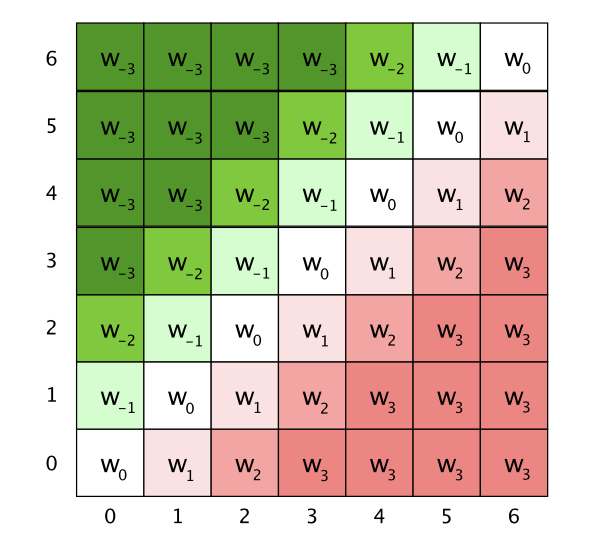
这里的位置编码PE是trainable的变量,为了控制模型参数的大小,同时保证位置编码可以generalize到任意文本长度,对相对位置做了截断,毕竟当前字符确实不太可能和距离太远的字符之前存在上下文交互,所以滑动窗口的设计也很合理。如果截断长度为k,位置编码PE的dim=2k+1,下图是k=3的/(R_{ij}/)
(Dai et al,2019)在Transformer-XL中给出了一种新的相对位置编码,几乎是和经典的绝对位置编码一一对应。
以上计算方案也被XLNET沿用,和RPR相比,Transfromer-XL
TENER是transformer在NER任务上的模型尝试,文章没有太多的亮点,更像是一篇用更合适的方法来解决问题的工程paper。沿用了Transformer-XL的相对位置编码, 做了两点调整,一个是key本身不做project,另一个就是在attention加权时没用对attenion进行scale, 也就是以下的归一化不再用/(/sqrt{d_k}/)对query和key的权重进行调整,得到的attenion会更加sharp。这个调整可以让权重更多focus在每个词的周边范围,更适用于局部建模的NER任务。
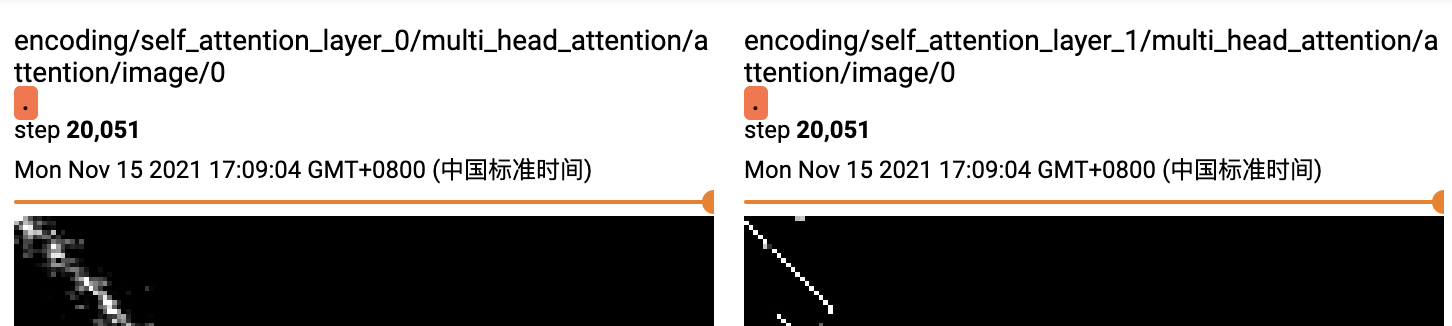
我们来直观对比下,同样的数据集和模型参数。绝对位置编码和unscale的相对位置编码attention的差异,这里都用了两层的transformer,上图是绝对位置编码,下图是unscale的相对位置编码。可以明显看到unscale的相对位置编码的权重,在第一层已经学习到部分周围信息后,第二层的attention范围进一步缩小集中在词周围(一定程度上说明可能1层transfromer就够用了),而绝对位置编码则相对分散在整个文本域。

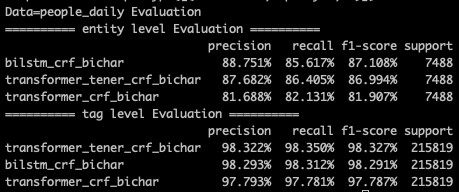
下面来对比下效果,transformer任务默认都是用的bichar输入,所以我们也和bilstm_bichar进行对比,在原paper中作者除了对句子部分使用transformer来提取信息,还在token粒度做了一层transformer,不过这里为了更公平的和bilstm对比,我们只保留了句子层面的transformer。以下是分别在MSRA和PeopleDaily两个任务上的效果对比。
只是把绝对位置编码替换成相对位置编码,在两个任务上都有4~5%的效果提升,最终效果也基本和bilstm一致。这里没做啥hyper search,参数给的比较小,整体上transformer任务扩大embedding,ffnsize效果会再有提升~

文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/123761.html

本文主要是给大家介绍了caffe的python插口生成deploy文件学习培训及其用练习好一点的实体模型(caffemodel)来归类新的图片实例详细说明,感兴趣的小伙伴可以参考借鉴一下,希望可以有一定的帮助,祝愿大家多多的发展,尽早涨薪 caffe的python插口生成deploy文件 假如要将练习好一点的实体模型用于检测新的图片,那必然必须得一个deploy.prototxt文件,这一...
摘要:特意对前端学习资源做一个汇总,方便自己学习查阅参考,和好友们共同进步。 特意对前端学习资源做一个汇总,方便自己学习查阅参考,和好友们共同进步。 本以为自己收藏的站点多,可以很快搞定,没想到一入汇总深似海。还有很多不足&遗漏的地方,欢迎补充。有错误的地方,还请斧正... 托管: welcome to git,欢迎交流,感谢star 有好友反应和斧正,会及时更新,平时业务工作时也会不定期更...
小编写这篇文章的一个主要目的,主要是给大家去做一个解答,解答的内容主要还是python相关事宜,比如,可以用python正则表达式去匹配和提取中文汉字,那么,具体的内容做法是什么呢?下面就给大家详细解答下。 python用正则表达式提取中文 Python re正则匹配中文,其实非常简单,把中文的unicode字符串转换成utf-8格式就可以了,然后可以在re中随意调用 unicode中中...
摘要:方法的参数不但可以使相对于上下文根的路径,而且可以是相对于当前的路径。如和都是合法的路径。 转发与重定向区别是什么 在调用方法上 转发 调用 HttpServletRequest 对象的方法 request.getRequestDispatcher(test.jsp).forward(req, resp); 重定向 调用 HttpServletResponse 对象的方法 res...
小编写这篇文章的主要目的,主要是用来给大家解释,Python Sklearn当中,一些实用的隐藏功能,大概有19条,这些实用的隐藏技能,会给我们的工作和生活带来很大的便利性,具体下文就给大家详细的介绍一下。 今天跟大家介绍19个Sklearn中超级实用的隐藏的功能,这些功能虽然不常见,但非常实用,它们可以直接优雅地替代手动执行的常见操作。接下来我们就一个一个介绍这些功能,希望对大家有所帮助!...

阅读 1759·2021-11-24 09:39
阅读 2565·2021-11-18 10:07
阅读 3774·2021-08-31 09:40
阅读 3492·2019-08-30 15:44
阅读 2684·2019-08-30 12:50
阅读 3704·2019-08-26 17:04
阅读 1507·2019-08-26 13:49
阅读 1314·2019-08-23 18:05



