
摘要:此处补充说明下,不论是还是都不提供指定区间的刷盘策略,只提供一个方法,所以无法精确控制落盘数据的大小。
由前文可知,RocketMQ有几个非常重要的概念:
既然是消息队列,那消息的存储的重要程度不言而喻,本节我们聚焦broker服务端,看下消息在broker端是如何存储的,它的落盘策略是怎样的,又是如何保证高效
另:后文的RocketMQ都是基于版本4.9.3
RocketMQ的普通单消息写入流程如下
简单可以分为三大块:
其实消息的写入准备工作也比较好理解,主要是消息状态的检查以及各类存储状态的检查,可以参看上图中的流程
根据上图,在准备阶段前,RocketMQ会判断操作系统的Page Cache是否繁忙,他是怎么做到的呢?其实Java本身没有提供接口或函数来查看Page Cache的状态,但如果磁盘带宽已经打满,在Page Cache要将数据刷disk时,很有可能便陷入了阻塞,导致Page Cache资源紧张。而当我们的程序又有新的消息要写入Page Cache时,反向阻塞写入请求,我们说这时Page Cache就产生了回压,也就是Page Cache相当繁忙,请求已经不能及时处理了。RocketMQ判断Page Cache是否繁忙的条件也很简单,就是监控某个请求加锁后,写入是否超过1秒,如果超时的话,新的请求会快速失败
RocketMQ有一套相对复杂的消息协议编码,大部分协议中的内容都是在加锁前拼接生成
大部分消息协议项都是定长字段,变长字段如下:
此处rmq提供了2种加锁方式
无论采用哪种策略,都是独占锁,即同一时刻只允许一个线程加锁成功。具体采用哪种方式,可通过配置修改。
两种加锁适用不同的场景,方式1在高并发场景下,能保持平稳的系统性能,但在低并发下表现一般;而方式二正好相反,在高并发场景下,因为采用自旋,会浪费大量的cpu,但在低并发时,却可以获得很高的性能。
所以官方文档中,为了提高性能,建议用户在同步刷盘的时候采用独占锁,异步刷盘的时候采用自旋锁。这个是根据加锁时间长短决定的
上文提到,写入消息的锁是独占锁,也就意味着同一时刻,只能有一个线程进入,我们看一下锁内都做了哪些操作
MappedFile文件的开辟是异步进行,有独立的线程专门负责开辟文件。我们可以先看下文件开辟的简单模型
也就是putMsg的线程会将开辟文件的请求委托给allocate file线程,然后进入阻塞,待allocate file线程将文件开辟完毕后,再唤醒putMsg线程
那此处我们便产生了2点疑问:
FileChannnel还是MappedByteBuffer,都是一件很快的操作,费尽周章的异步开辟真的有必要吗?这两个疑问将逐步说明
至此我们要引入一个非常重要的配置变量transientStorePoolEnable,该配置项只在异步刷盘(FlushDiskType == AsyncFlush)的场景下,才会生效
如果配置项中,将transientStorePoolEnable置为false,便称为“开启堆外缓冲池”。那么这个变量到底起到什么作用呢?

系统启动时,会默认开辟5个(参数transientStorePoolSize控制)堆外内存DirectByteBuffer,循环利用。写消息时,消息都暂存至此,通过线程CommitRealTimeService将数据定时刷到page cache,当数据flush到disk后,再将DirectByteBuffer归还给缓冲池
而开辟过程是在broker启动时进行的;如上图所示,空间一旦开辟完毕后,文件都是预先创建好的,使用时直接返回文件引用即可,相当高效。但首次启动需要大量开辟堆外内存空间,会拉长broker的启动时长。我们看一下这块开辟的源码
/** * Its a heavy init method. */public void init() { for (int i = 0; i < poolSize; i++) { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(fileSize); ...... availableBuffers.offer(byteBuffer); }}注释中也标识了这是个重量级的方法,主要耗时点在ByteBuffer.allocateDirect(fileSize),其实开辟内存并不耗时,耗时集中在为内存区域赋0操作,以下是JDK中DirectByteBuffer源码:
DirectByteBuffer(int cap) { // package-private super(-1, 0, cap, cap); ...... long base = 0; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); ......}我们发现在开辟完内存后,开始执行了赋0操作unsafe.setMemory(base, size, 0)。其实可以利用反射巧妙地绕过这个耗时点
private static Field addr;private static Field capacity;static { try { addr = Buffer.class.getDeclaredField("address"); addr.setAccessible(true); capacity = Buffer.class.getDeclaredField("capacity"); capacity.setAccessible(true); } catch (NoSuchFieldException e) { e.printStackTrace(); }}public static ByteBuffer newFastByteBuffer(int cap) { long address = unsafe.allocateMemory(cap); ByteBuffer bb = ByteBuffer.allocateDirect(0).order(ByteOrder.nativeOrder()); try { addr.setLong(bb, address); capacity.setInt(bb, cap); } catch (IllegalAccessException e) { return null; } bb.clear(); return bb;}关闭堆外内存池的话,就会启动MappedByteBuffer

我们再回顾一下本章刚开始提出的2个疑问:
FileChannnel还是MappedByteBuffer,都是一件很快的操作,费尽周章的异步开辟真的有必要吗?第一个问题已经迎刃而解,即allocate线程通过异步创建下一个文件的方式,实现真正异步
本节讨论的便是第二个问题,其实如果只是单纯创建文件的话,的确是非常快的,不至于再使用异步操作。但RocketMQ对于新建文件有个文件预热(通过配置warmMapedFileEnable启停)功能,当然目的是为了磁盘提速,我么先看下源码
org.apache.rocketmq.store.MappedFile#warmMappedFile
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) { byteBuffer.put(i, (byte) 0); // force flush when flush disk type is sync if (type == FlushDiskType.SYNC_FLUSH) { if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) { flush = i; mappedByteBuffer.force(); } }}简单来说,就是将MappedByteBuffer每隔4K就写入一个0 byte,然后将整个文件撑满;如果刷盘策略是同步刷盘的话,还需要调用mappedByteBuffer.force(),当然这个操作是相当相当耗时的,所以也就需要我们进行异步处理。这样也就解释了第二个问题
但文件预热真的有效吗?我们不妨做个简单的基准测试
public class FileWriteCompare { private static String filePath = "/Users/likangning/test/index3.data"; private static int fileSize = 1024 * 1024 * 1024; private static boolean warmFile = true; private static int batchSize = 4096; @Test public void test() throws Exception { File file = new File(filePath); if (file.exists()) { file.delete(); } file.createNewFile(); FileChannel fileChannel = FileChannel.open(file.toPath(), StandardOpenOption.WRITE, StandardOpenOption.READ); MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize); ByteBuffer byteBuffer = ByteBuffer.allocateDirect(batchSize); long beginTime = System.currentTimeMillis(); mappedByteBuffer.position(0); while (mappedByteBuffer.remaining() >= batchSize) { byteBuffer.position(batchSize); byteBuffer.flip(); mappedByteBuffer.put(byteBuffer); } System.out.println("time cost is : " + (System.currentTimeMillis() - beginTime)); }}简单来说就是通过MappedByteBuffer写入1G文件,在我本地电脑上,平均耗时在 550ms 左右
然后在MappedByteBuffer写文件前加入预热操作
private void warmFile(MappedByteBuffer mappedByteBuffer) { if (!warmFile) { return; } int pageSize = 4096; long begin = System.currentTimeMillis(); for (int i = 0, j = 0; i < fileSize; i += pageSize, j++) { mappedByteBuffer.put(i, (byte) 0); } System.out.println("warm file time cost " + (System.currentTimeMillis() - begin));}耗时情况如下:
warm file time cost 492time cost is : 125预热后,写文件的耗时缩短了很多,但预热本身的耗时也几乎等同于文件写入的耗时了
以上是没有强制刷盘的测试效果,如果强制刷盘(#force)的话,个人经验是文件预热一定会带来性能的提升。从前两天结束的第二届中间件性能挑战赛来看,文件预热至少带来10%以上的提升。但是同非强制刷盘一样,文件预热操作实在是太重了
整体来看,文件预热后的写入操作,确实能带来性能上的提升,但是如果在系统压力较大、磁盘吞吐紧张的场景下,势必导致broker抖动,甚至请求超时,反而得不偿失。明白了此层概念后,再通过大量benchmark来决定是否开启此配置,做到有的放矢
经过以上整理分析后,文件写入将变得非常轻;不论是DirectByteBuffer还是MappedByteBuffer都可以抽象为ByteBuffer,进而直接调用ByteBuffer.write()

对应如下配置
FlushDiskType == AsyncFlush && transientStorePoolEnable == false异步刷盘,且关闭缓冲池,对应的异步刷盘线程是FlushRealTimeService
上文可知,次策略是通过MappedByteBuffer写入的数据,所以此时数据已经在 page cache 中了
我们总结一下刷盘的策略:
不响应中断,固定500ms(可配置)刷盘,但刷盘的时候,如果发现未落盘数据不足16K(可配置),那么将进入下一个循环,如果满16K的话,会将所有未落盘的数据落盘。此处补充说明下,不论是FileChannel还是MappedByteBuffer都不提供指定区间的刷盘策略,只提供一个force()方法,所以无法精确控制落盘数据的大小。
如果数据写入量很少,一直没有填充满16K,就不会落盘了吗?不是的,此处兜底的方案是,线程发现距离上次无条件全量刷盘已经超过10000ms(可配置),那么此时就会无条件触发全量刷盘
与「固定频率刷盘」比较相似,唯一不同点是,当前刷盘策略是响应中断的,即每次有新的消息到来的时候,都会发送唤醒信号,如果刷盘线程正好处在500ms等待期间的话,将被唤醒。但此处的唤醒并非严谨的唤醒,有可能发送了唤醒信号,但刷盘线程并未成功响应,兜底方案便是500ms的重试。下面简单黏贴一下等待、唤醒的代码,不再赘述
org.apache.rocketmq.common.ServiceThread
// 唤醒public void wakeup() { if (hasNotified.compareAndSet(false, true)) { waitPoint.countDown(); // notify }}// 睡眠并响应唤醒protected void waitForRunning(long interval) { if (hasNotified.compareAndSet(true, false)) { this.onWaitEnd(); return; } //entry to wait waitPoint.reset(); try { waitPoint.await(interval, TimeUnit.MILLISECONDS); } catch (InterruptedException e) { log.error("Interrupted", e); } finally { hasNotified.set(false); this.onWaitEnd(); }}综上,数据在page cache中最长的等待时间为(10000+500)ms
对应如下配置
FlushDiskType == AsyncFlush && transientStorePoolEnable == true异步刷盘,且开启缓冲池,对应的异步刷盘线程是CommitRealTimeService
首先需要明确一点的是,当前配置下,在写入阶段,数据是直接写入DirectByteBuffer的,这样做的好处及弊端也非常鲜明。
DirectByteBuffer后便很快返回,减少了用户态与内核态的切换开销,性能非常高值得一提的是,此种刷盘模式,写入动作使用的是FileChannel,且仅仅调用FileChannel.write()方法将数据写入page cache,并没有直接强制刷盘,而是将强制落盘的任务转交给FlushRealTimeService线程来操作,而FlushRealTimeService线程最终也会调用FileChannel进行强制刷盘
在RocketMQ内部,无论采用什么刷盘策略,都是单一操作对象在写入/读取文件;即如果使用MappedByteBuffer写文件,那一定会通过MappedByteBuffer刷盘,如果使用FileChannel写文件,那一定会通过FileChannel 刷盘,不存在混合操作的情况
疑问:为什么RocketMQ不依赖操作系统的异步刷盘,而费劲周章的设计如此刷盘策略呢?
个人理解,作为一个成熟开源的组件,数据的安全性至关重要,还是要尽可能保证数据稳步有序落盘;OS的异步刷盘固然好使,但RocketMQ对其把控较弱,当操作系统crash或者断电的时候,造成的数据丢失影响不可控
需要说明的是,如果FlushDiskType配置的是同步刷盘的话,那么此处数据一定已经被MappedByteBuffer写入了pageCache,接下来要做的便是真正的落盘操作。与异步落盘相似,同步落盘要根据配置项Message.isWaitStoreMsgOK()(等待消息落盘)来分别说明
同步刷盘的落盘线程统一都是GroupCommitService

当前模式如图所示,整体流程比较简单,写入线程仅仅负责唤醒落盘线程,然后便执行后续逻辑,线程不阻塞;落盘线程每次休息10ms(可被写入线程唤醒)后,如果发现有数据未落盘,便将page cache中的数据强制force到磁盘
我们发现,其实相比较异步刷盘来说,同步刷盘轮训的时间只有10ms,远小于异步刷盘的500ms,也是比较好理解的。但当前模式写入线程不会阻塞,也就是不会等待消息真正存储到disk后再返回,如果此时反生操作系统crash或者断电,那未落盘的数据便会丢失
个人感觉,将FlushDiskType已经设置为Sync,表明数据会强制落盘,却又引入Message.isWaitStoreMsgOK(),来左右落盘策略,多多少少会给使用者造成使用及理解上的困惑
相比较上文,本小节便是数据需要真正存储到disk后才进行返回。写入线程在唤醒落盘线程后便进入阻塞,直至落盘线程将数据刷到disk后再将其唤醒
不过这里需要处理一个边界问题,即旧CommitLog的tail,及新CommitLog的head。例如现在有2个写入线程将数据写入了page cache,而这2个请求一个落在前CommitLog的尾部,另外一个落在新CommitLog的头部,这个时候,落盘线程需要检测到这两个消息的分布,然后依次将两个CommitLog数据落盘
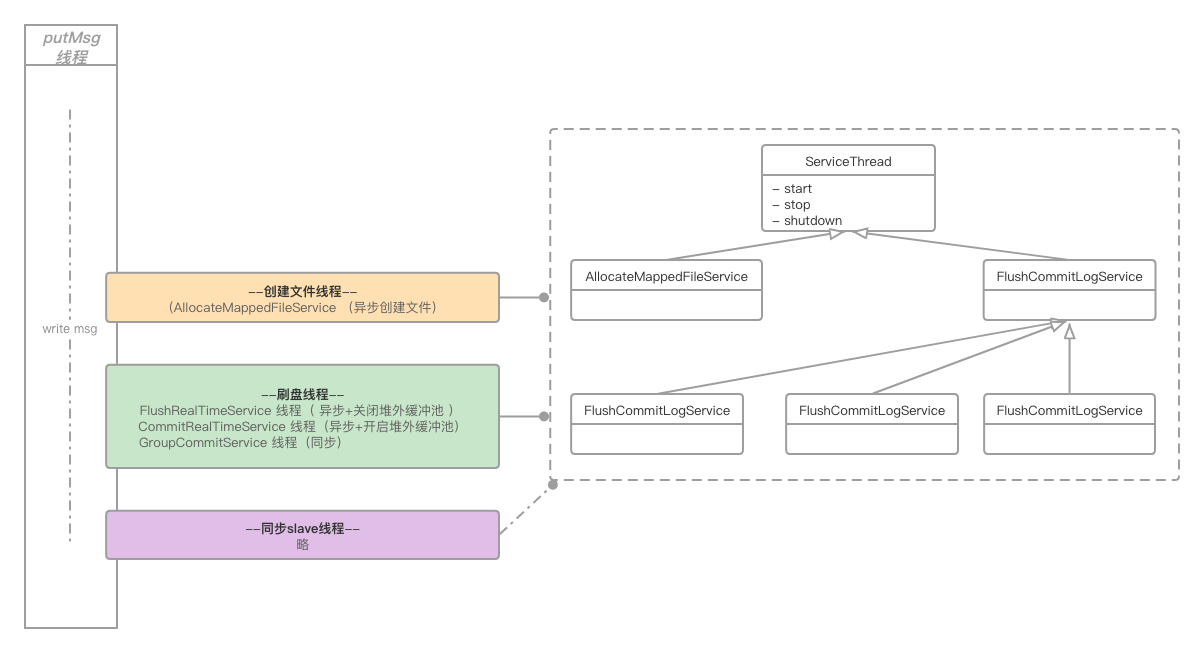
RocketMQ中所有的异步处理线程都继承自抽象类org.apache.rocketmq.common.ServiceThread,此类定义了简单的唤醒、通知模型,但并不严格保证唤醒,而是通过轮训作为兜底方案。实测发现唤醒动作在数据量较大时,存在性能损耗,改为简单的轮询落盘模式,性能提高明显
本章我们聚焦分析了一条消息在broker端落地的全过程,但整个流程还是比较复杂的,不过有些部分没有提及(比如说消息在master落地后是如何同步至salve端的),主要是考虑这些部分跟存储关联度不是很强,放在一起思路容易发散,这些部分会放在后文专门开标题阐述
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/123639.html
摘要:它是阿里巴巴于年开源的第三代分布式消息中间件。是一个分布式消息中间件,具有低延迟高性能和可靠性万亿级别的容量和灵活的可扩展性,它是阿里巴巴于年开源的第三代分布式消息中间件。上篇文章消息队列那么多,为什么建议深入了解下RabbitMQ?我们讲到了消息队列的发展史:并且详细介绍了RabbitMQ,其功能也是挺强大的,那么,为啥又要搞一个RocketMQ出来呢?是重复造轮子吗?本文我们就带大家来详...
摘要:主流消息中间件介绍是由出品,是一个完全支持和规范的实现。主流消息中间件介绍是阿里开源的消息中间件,目前也已经孵化为顶级项目。 showImg(https://img-blog.csdnimg.cn/20190509221741422.gif);showImg(https://img-blog.csdnimg.cn/20190718204938932.png?x-oss-process=...
摘要:故事中的下属们,就是消息生产者角色,屋子右面墙根那块地就是消息持久化,吕秀才就是消息调度中心,而你就是消息消费者角色。下属们汇报的消息,应该叠放在哪里,这个消息又应该在哪里才能找到,全靠吕秀才的惊人记忆力,才可以让消息准确的被投放以及消费。 微信公众号:IT一刻钟大型现实非严肃主义现场一刻钟与你分享优质技术架构与见闻,做一个有剧情的程序员关注可了解更多精彩内容。问题或建议,请公众号留言...
摘要:故事中的下属们,就是消息生产者角色,屋子右面墙根那块地就是消息持久化,吕秀才就是消息调度中心,而你就是消息消费者角色。下属们汇报的消息,应该叠放在哪里,这个消息又应该在哪里才能找到,全靠吕秀才的惊人记忆力,才可以让消息准确的被投放以及消费。 微信公众号:IT一刻钟大型现实非严肃主义现场一刻钟与你分享优质技术架构与见闻,做一个有剧情的程序员关注可了解更多精彩内容。问题或建议,请公众号留言...

阅读 828·2023-04-25 19:43
阅读 4075·2021-11-30 14:52
阅读 3903·2021-11-30 14:52
阅读 3992·2021-11-29 11:00
阅读 3891·2021-11-29 11:00
阅读 4013·2021-11-29 11:00
阅读 3725·2021-11-29 11:00
阅读 6445·2021-11-29 11:00





