
摘要:很好解决,采用排序算法进行排序即可。处理方式是记录顶点在最小生成树中的终点,顶点的终点是在最小生成树中与它连通的最大顶点。如何判断回路将所有顶点按照从小到大的顺序排列好之后,某个顶点的终点就是与它连通的最大顶点。
①对图的所有边按照权值大小进行排序。
②将边添加到最小生成树中时,怎么样判断是否形成了回路。
①很好解决,采用排序算法进行排序即可。
②处理方式是:记录顶点在"最小生成树"中的终点,顶点的终点是"在最小生成树中与它连通的最大顶点"。然后每次需要将一条边添加到最小生存树时判断该边的两个顶点的终点是否重合,重合的话则会构成回路。
将所有顶点按照从小到大的顺序排列好之后,某个顶点的终点就是"与它连通的最大顶点"。我们加入的边的两个顶点不能都指向同一个终点,否则构成回路。
具体是这个方法
/** * 返回传入的点的终点的下标 * @param ends ends[i] = j i是传入的点的下标,j是i的相邻点的下标 * @param i * @return */public static int getEnd(int[] ends,int i){ //如果这个点有可以到达的点,那么就把可以到达的点赋值到i,然后如果i还有可以到达的点,那么就重复此操作。一直到最后,最后的点就是最初传入的点的终点 //其实ends数组记的是每一个点的相邻点,而不是终点,但是可以通过ends数组,利用while循环,求出一个点的终点 while (ends[i] != 0){ i = ends[i]; } return i;}public class Main { static char[] data = {"A","B","C","D","E","F","G"}; public static void main(String[] args) { //char[] data = {"A","B","C","D","E","F","G"}; int[][] weight = { {0,12,10000,10000,10000,16,14}, {12,0,10,10000,10000, 7,10000}, {10000,10,0,3,5,6,10000}, {10000,10000,3,0,4,10000,10000}, {10000,10000,5,4,0,2,8}, {16,7,6,10000,2,0,9}, {14,10000,10000,10000,8,9,0}}; MGraph mGraph = new MGraph(data.length); mGraph.createGraph(data,weight); mGraph.showGraph(); createMinTreeKruskal(mGraph); //System.out.println(Arrays.toString(MEdge.getEdges(mGraph))); //System.out.println(Arrays.toString(MEdge.getSortedEdges(MEdge.getEdges(mGraph)))); } /** * 克鲁斯卡尔算法构建最小生成树 */ public static void createMinTreeKruskal(MGraph mGraph){ if (mGraph.vertexNum == 0){ return; } //首先得到传入的图的所有边按权值从小到大的顺序排序 MEdge[] sortedEdges = MEdge.getSortedEdges(MEdge.getEdges(mGraph));//所有边 ArrayList<MEdge> mEdges = new ArrayList<>(); //创建所有顶点的终点集 int[] ends = new int[mGraph.vertexNum]; for (int i = 0;i < sortedEdges.length;i++){ int p1 = MEdge.getPointIndex(sortedEdges[i].startPoint,data); int p2 = MEdge.getPointIndex(sortedEdges[i].endPoint,data); //判断此边的两个点的终点是否相同 int end1 = MEdge.getEnd(ends,p1); int end2 = MEdge.getEnd(ends,p2); if (end1 != end2){ ends[end1] = end2; mEdges.add(sortedEdges[i]); } } System.out.println(mEdges); }}//创建边class MEdge{ char startPoint; char endPoint; int weight; public MEdge(char startPoint, char endPoint, int weight) { this.startPoint = startPoint; this.endPoint = endPoint; this.weight = weight; } @Override public String toString() { return "MEdge{" + "startPoint=" + startPoint + ", endPoint=" + endPoint + ", weight=" + weight + "}"; } //传入一个图,根据其邻接矩阵,得到其边的数目 public static int getEdgesNum(MGraph mGraph){ if (mGraph.vertexNum == 0){ return -1; } int edgeNum = 0; for (int i = 0;i < mGraph.vertexNum;i++){ for(int j = i + 1;j < mGraph.vertexNum;j++){ if (mGraph.weight[i][j] != 10000){ //说明这是一条边,i和j分别是其端点 edgeNum++; } } } return edgeNum; } //传入一个图,根据其邻接矩阵,得到其边 public static MEdge[] getEdges(MGraph mGraph){ if (mGraph.vertexNum == 0){ return null; } MEdge[] mEdges = new MEdge[getEdgesNum(mGraph)]; int index = 0; for (int i = 0;i < mGraph.vertexNum;i++){ for(int j = i + 1;j < mGraph.vertexNum;j++){ if (mGraph.weight[i][j] != 10000){ //说明这是一条边,i和j分别是其端点 mEdges[index] = new MEdge(mGraph.data[i],mGraph.data[j],mGraph.weight[i][j]); index++;//这里一定别忘了+1 } } } return mEdges; } //传入一个边集合,根据其权值大小进行排序 public static MEdge[] getSortedEdges(MEdge[] mEdges){ for (int i = 0;i < mEdges.length - 1;i++){ for (int j = 0;j < mEdges.length - i - 1;j++){ if (mEdges[j + 1].weight < mEdges[j].weight){ //不能用下面的 因为下面这种仅仅改变了边的权,我们应该整个边都去改变// int temp = mEdges[j + 1].weight;// mEdges[j + 1].weight = mEdges[j].weight;// mEdges[j].weight = temp; MEdge mEdge = mEdges[j + 1]; mEdges[j + 1] = mEdges[j]; mEdges[j] = mEdge; } } } return mEdges; } /** * 返回传入的点的终点的下标 * @param ends ends[i] = j i是传入的点的下标,j是i的终点的下标 * @param i * @return */ public static int getEnd(int[] ends,int i){ //如果这个点有可以到达的点,那么就把可以到达的点赋值到i,然后如果i还有可以到达的点,那么就重复此操作。 //其实ends数组记的是每一个点的相邻点,而不是终点,但是可以通过ends数组,利用while循环,求出一个点的终点 while (ends[i] != 0){ i = ends[i]; } return i; } //输入一个顶点(char类型),返回其索引值(int类型) public static int getPointIndex(char point,char[] datas){ for (int i = 0;i < datas.length;i++){ if (datas[i] == point){ return i; } } return -1;//没找到 }}//这是图class MGraph{ //节点数目 int vertexNum; //节点 char[] data; //边的权值 int[][] weight; MGraph(int vertexNum){ this.vertexNum = vertexNum; data = new char[vertexNum]; weight = new int[vertexNum][vertexNum]; } //图的创建 public void createGraph(char[] mData,int[][] mWeight){ if (vertexNum == 0){ return;//节点数目为0 无法创建 } for (int i = 0;i < data.length;i++){ data[i] = mData[i]; } for (int i = 0;i < mWeight.length;i++){ for (int j = 0;j < mWeight.length;j++){ weight[i][j] = mWeight[i][j]; } } } //打印图 public void showGraph(){ if (vertexNum == 0){ return; } for (int[] oneLine: weight){ for (int oneNum: oneLine){ System.out.printf("%20d",oneNum); } System.out.println(); } }}结果
0 12 10000 10000 10000 16 14 12 0 10 10000 10000 7 10000 10000 10 0 3 5 6 10000 10000 10000 3 0 4 10000 10000 10000 10000 5 4 0 2 8 16 7 6 10000 2 0 9 14 10000 10000 10000 8 9 0[MEdge{startPoint=E, endPoint=F, weight=2}, MEdge{startPoint=C, endPoint=D, weight=3}, MEdge{startPoint=D, endPoint=E, weight=4}, MEdge{startPoint=B, endPoint=F, weight=7}, MEdge{startPoint=E, endPoint=G, weight=8}, MEdge{startPoint=A, endPoint=B, weight=12}]文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/121401.html
摘要:应用分治法是一种很重要的算法。字面上的解释是分而治之,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。 ...
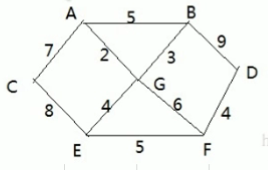
摘要:问题胜利乡有个村庄现在需要修路把个村庄连通各个村庄的距离用边线表示权比如距离公里问如何修路保证各个村庄都能连通并且总的修建公路总里程最短代码重点理解中的三层循环 问...
摘要:递归实现不考虑相同数二分查找,不考虑有相同数的情况递归找到了考虑有相同数二分查找考虑有相同元素的情况递归要查找的值 1.递归实现 ①不考虑相同数 /** * 二分查...
摘要:学习资料迪杰斯特拉计算的是单源最短路径,而弗洛伊德计算的是多源最短路径代码不能设置为,否则两个相加会溢出导致出现负权创建顶点和边 学习资料 迪杰斯特拉计算的是单源最...
摘要:例题假设存在如下表的需要付费的广播台,以及广播台信号可以覆盖的地区。 例题 假设存在如下表的需要付费的广播台,以及广播台信号可以覆盖的地区。如何选择最少的广播台,让...

阅读 2496·2023-04-25 20:07
阅读 3395·2021-11-25 09:43
阅读 3800·2021-11-16 11:44
阅读 2634·2021-11-08 13:14
阅读 3259·2021-10-19 11:46
阅读 981·2021-09-28 09:36
阅读 3208·2021-09-22 10:56
阅读 2467·2021-09-10 10:51






