
摘要:例题假设存在如下表的需要付费的广播台,以及广播台信号可以覆盖的地区。
假设存在如下表的需要付费的广播台,以及广播台信号可以覆盖的地区。如何选择最少的广播台,让所有的地区都可以接收到信号
public class Main { public static void main(String[] args) { /** * 1.首先创建总的广播台和电视台 */ //创建一个总的 能装得下所有的广播台和电视台 HashMap<String, HashSet<String>> broadcastsAndCitys = new HashMap<>(); //分别创建每一个广播台的覆盖地区,然后加到总的集合中 HashSet<String> K1 = new HashSet<>(); K1.add("北京"); K1.add("上海"); K1.add("天津"); HashSet<String> K2 = new HashSet<>(); K2.add("广州"); K2.add("北京"); K2.add("深圳"); HashSet<String> K3 = new HashSet<>(); K3.add("成都"); K3.add("上海"); K3.add("杭州"); HashSet<String> K4 = new HashSet<>(); K4.add("上海"); K4.add("天津"); HashSet<String> K5 = new HashSet<>(); K5.add("杭州"); K5.add("大连"); //然后将每一个覆盖地区,以及广播台名,加入到总的集合中 broadcastsAndCitys.put("k1",K1); broadcastsAndCitys.put("k2",K2); broadcastsAndCitys.put("k3",K3); broadcastsAndCitys.put("k4",K4); broadcastsAndCitys.put("k5",K5); System.out.println(broadcastsAndCitys);//{k1=[上海, 天津, 北京], k2=[广州, 北京, 深圳], k3=[成都, 上海, 杭州], k4=[上海, 天津], k5=[大连, 杭州]} /** * 2.进行贪心算法初始化操作,比如创建包含所有城市的集合,创建选择的电台的集合,创建一个 电台与包含所有城市集合的交集所构成的集合 */ HashSet<String> allCitys = new HashSet<String>(); allCitys.add("北京"); allCitys.add("上海"); allCitys.add("天津"); allCitys.add("广州"); allCitys.add("深圳"); allCitys.add("成都"); allCitys.add("杭州"); allCitys.add("大连"); HashSet<String> selectBroadcasts = new HashSet<>(); HashSet<String> tempKeys = new HashSet<>(); //创建指向最大城市数的key的引用,以及指向当前广播台的key String maxKey = null; /** * 3.进行正儿八经的贪心算法 */ while (allCitys.size() > 0){//只有长度不为0的时候才可以继续,否则就是已经选好了 //每一次while maxKey都要置空 maxKey = null; //从broadcastsAndCitys中依次取出key,经过循环赋值,得到maxKey for (String key: broadcastsAndCitys.keySet()){ //因为tempKeys是针对每一个key的,所以每取得一个key就要清空一次 tempKeys.clear(); //给tempKeys赋值 HashSet<String> hashSet = broadcastsAndCitys.get(key);//!!!这里要重新创建一个集合去接收!!! tempKeys.addAll(hashSet); //tempKeys = broadcastsAndCitys.get(key); //让当前key和allCitys取交集,得其包括的城市数 tempKeys.retainAll(allCitys); //给maxKey赋值 if (tempKeys.size() > 0 && (maxKey == null || tempKeys.size() > broadcastsAndCitys.get(maxKey).size())){ //不管怎么着,得有城市才能赋值 //maxKey为空说明还没赋过值呢,就直接赋值 //tempKeys里面有东西,且东西的数目比当前maxKey指向的数目要多(没有等于,如果相等,maxKey就指向第一个) maxKey = key; } } if (maxKey != null){ //把选出来的maxKey加进去selectBroadcasts selectBroadcasts.add(maxKey); //把选出来的maxKey覆盖的城市从allCitys中去掉 allCitys.removeAll(broadcastsAndCitys.get(maxKey)); }else { //如果比较下来都没有一个合适的maxKey,而且allCitys.size()还可能>0,那么很遗憾,可能只能找到最接近需求的解 break; } } System.out.println(selectBroadcasts); }}结果
{k1=[上海, 天津, 北京], k2=[广州, 北京, 深圳], k3=[成都, 上海, 杭州], k4=[上海, 天津], k5=[大连, 杭州]}[k1, k2, k3, k5]addAll是传入一个List,将此List中的所有元素加入到当前List中
public classTest { public static void main(String[] args) { HashMap<String, HashSet<String>> broadcastsAndCitys = new HashMap<>(); HashSet<String> test1 = new HashSet<>(); test1.add("我"); test1.add("是"); test1.add("最"); test1.add("帅"); broadcastsAndCitys.put("k1",test1); //test3是要被交集的 HashSet<String> test3 = new HashSet<>(); test3.add("我"); //test2是保存交集的 HashSet<String> test2 = new HashSet<>(); //test2把test1拿出来,与test3取交集,赋给test2 test2 = broadcastsAndCitys.get("k1"); test2.retainAll(test3); //结果test1变成了test2,就是取完交集的那个结果,这里就是打印1 因为只有一个交集 System.out.println(broadcastsAndCitys.get("k1").size()); //原因:test2把test1拿出来,意味着test2和test1指向了相同的位置,相同的内存空间 //如果重新创建一个HashSet来保存test1,然后再与test3取交集 HashSet<String> test4 = broadcastsAndCitys.get("k1"); test2.addAll(test4);//注意用addAll方法 test2.retainAll(test3); //这里就是打印4 因为原来的没变 System.out.println(broadcastsAndCitys.get("k1").size()); //原因:test4在与test2发生关系的时候,用了addAll方法,这个方法是把test4的所有元素的内容加进去 //此时test2相当于指向了另一块内存空间,其内容与test4是一样的 }}文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/121270.html
摘要:骑士周游问题又叫马踏棋盘问题未优化前没有策略定义棋盘的行数和列数定义棋盘上的某个点是否被访问过记录是否周游结束从第一行第一列开始走,第一次走算第一步,即展示下是棋盘, ...
摘要:应用分治法是一种很重要的算法。字面上的解释是分而治之,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。 ...
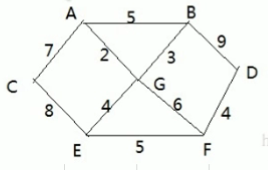
摘要:问题胜利乡有个村庄现在需要修路把个村庄连通各个村庄的距离用边线表示权比如距离公里问如何修路保证各个村庄都能连通并且总的修建公路总里程最短代码重点理解中的三层循环 问...
摘要:递归实现不考虑相同数二分查找,不考虑有相同数的情况递归找到了考虑有相同数二分查找考虑有相同元素的情况递归要查找的值 1.递归实现 ①不考虑相同数 /** * 二分查...
摘要:学习资料迪杰斯特拉计算的是单源最短路径,而弗洛伊德计算的是多源最短路径代码不能设置为,否则两个相加会溢出导致出现负权创建顶点和边 学习资料 迪杰斯特拉计算的是单源最...

阅读 1421·2021-11-25 09:43
阅读 2278·2021-09-27 13:36
阅读 1132·2021-09-04 16:40
阅读 1979·2019-08-30 11:12
阅读 3332·2019-08-29 14:14
阅读 585·2019-08-28 17:56
阅读 1346·2019-08-26 13:50
阅读 1266·2019-08-26 13:29






